
머신러닝 Classification
이번 포스트부터는 머신러닝의 세부적인 문제들에 대해서 알아볼텐데요. 먼저, 분류 Classification의 대표적인 데이터 셋인 MNIST 데이터셋을 활용해서 분류 문제에 대해서 알아보겠습니다.
MNIST
MNIST는 실제 사람이 0부터 9까지의 숫자를 손글씨로 쓴 이미지 데이터셋 입니다. Classification은 supervised 문제이기 때문에 input data와 label로 데이터셋이 구성되어 있겠죠. Scikit-Learn에서 MNIST 데이터셋을 가져와서 한번 살펴보겠습니다.
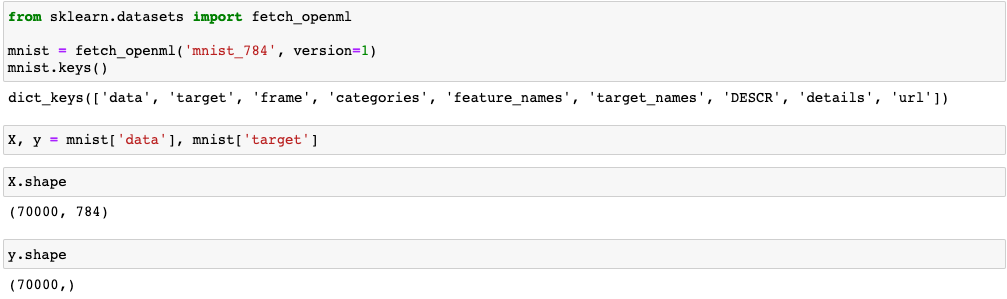
여기서 X는 실제 손글씨의 이미지 데이터고 y는 이게 어떤 숫자인지 label에 해당됩니다. 데이터 shape을 확인해봤을 때, 총 데이터는 7만개이고 이미지는 784 크기의 벡터로 표현된 것을 확인할 수 있습니다. 이미지도 자연어와 마찬가지로 컴퓨터가 이해할 수 있도록 표현해줘야 하겠죠. 784개의 feature는 이미지의 하나의 pixel이라고 보면 됩니다. 그렇다면 784 크기의 벡터는 28X28를 1차원으로 벡터화 시켰다고 볼 수 있겟죠. CNN 등의 이미지를 처리하는 알고리즘을 알아볼 때, 자세히 다루겠지만 RGB를 통해 색을 표현하기 위해 채널이라는 개념을 도입하기도 하는데요. 이는 추후에 자세히 알아보겠습니다.
그럼, 1차원 벡터로 표현되어있는 MNIST 데이터 셋 중 하나를 이미지로 표현해보겠습니다.
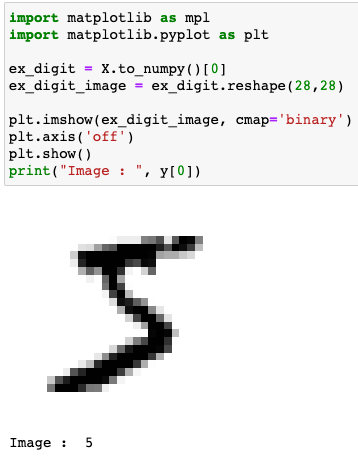
이미지 상으로 5처럼 보이는데요, label을 확인했을 때도 5인 것을 확인할 수 있습니다. 이제 데이터를 확인해봤으니 데이터 셋을 훈련/테스트 용으로 구분을 지어보겠습니다. 아 그전에 label 데이터가 문자형으로 되어있는 것을 숫자로 바꿔줘야 합니다.
import numpy as np
y = y.astype(np.uint8)
Scikit_learn에서 제공하는 MNIST 데이터셋은 고맙게도 훈련/테스트 용으로 구분(60000:10000)이 되어있습니다. 이전 장에서 해줬던 shuffle이나 클래스 별로 비율을 유지하도록 처리해줘야 하는 작업이 이미 적용되어 있어서 여기서는 구분만 해주면 됩니다. 어렵지 않게 간단한 indexing을 통해서 진행할 수 있습니다.
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
Training a Binary Classifier
Classification 문제는 크게 두 가지로 구분할 수 있는데요, 하나는 이진 분류 Binary Classifciation이고 다른 하나는 다중 분류 Multiclass Classification입니다.
이진분류는 말 그대로 Class가 두개 즉, ~이냐 아니냐에 대한 문제이죠. 예를 들어서, 강아지와 고양이를 구분하는 문제 또는 강아지이냐 아니냐를 구분하는 문제가 있겠습니다.
MNIST 데이터셋을 활용해서 이미지가 숫자 5인지 아닌지 구분할 수 있는 문제를 통해 이진분류에 대해서 알아보겠습니다. 먼저, 문제에 맞게 데이터 셋을 전처리 해줍니다.
y_train_5 = (y_train==5)
y_test_5 = (y_test==5)
이렇게 처리를 해주면 label이 숫자에서 bool 형태인 True, False로 바뀌게 됩니다. 이제 모델을 선택하고 훈련을 진행해보죠. SGD 방식의 Linear Classifier (Logistic Regression, SVM, Perceptro)를 모델로 해서 진행해보겠습니다. SGD는 Stochasitc Gradient Descent로 모델을 훈련하는 방식 중 하나입니다. 다음 장에 자세한 내용을 다룰 예정이니 여기서는 훈련 방식 중 하나이구나 라고 생각하고 넘어가면 됩니다.
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(random_state=42, loss='hinge') #hinge => SVM
sgd_clf.fit(X_train, y_train_5)
이렇게 SVM 기반의 linear 모델을 SGD 방식으로 기존의 이미지 데이터와 5인지 아닌지에 대해서 변형시켜준 label 데이터를 통해 훈련을 시켜줍니다. 그럼 test 데이터를 통해 결과를 확인해보겠습니다.
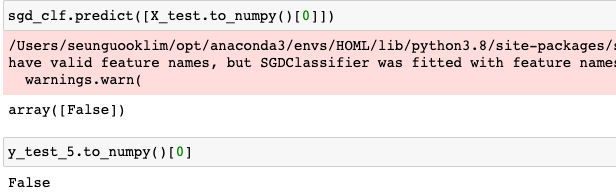
테스트 데이터 셋에 대해서 예측을 했을 때, 적절하게 동작하는 것을 확인할 수 있습니다. 모든 데이터에 대해서 하나하나씩 살펴보는 것은 힘들겠죠. 지금부터는 Classification 문제에 대해서 모델을 평가하는 성능과 측정 방법에 대해서 알아보겠습니다.
Performance Measures
Accuracy
정확도 Accuracy는 말 그대로 모델이 정답을 얼마나 맞췄는지에 대한 지표입니다. 구하는 공식도 간단합니다. 데이터 셋을 하나의 문제라고 한다면 정확도는 문제들 중에 정답의 비율입니다. 예를 들어서, 5개의 강아지 사진과 5개의 고양이 사진이 있을 때, 사진이 강아지인지 아닌지를 맞춘다고 가정을 해보죠. 이 때, 정확도는 모델이 강아지 사진을 강아지라고 했을 경우와 고양이 사진을 강아지가 아니라고 했을 경우를 더한 후, 전체 사진의 수로 나누면 됩니다. 어렵지 않죠?
그렇다면 MNIST를 활용해 정확도를 구해보겠습니다. 이전 장에서 다뤘던 cross-validation을 적용해보죠.
from sklearn.model_selection import StratifiedKFold
from sklearn.base import clone
skfolds = StratifiedKFold(n_splits=3)
sgd_clf = SGDClassifier(random_state=42, loss='hinge') #hinge => SVM
for train_index, test_index in skfolds.split(X_train, y_train_5):
clone_clf = clone(sgd_clf)
X_train_folds = X_train.iloc[train_index]
y_train_folds = y_train_5[train_index]
X_test_fold = X_train.iloc[test_index]
y_test_fold = y_train_5[test_index]
clone_clf.fit(X_train_folds, y_train_folds)
y_pred = clone_clf.predict(X_test_fold)
n_correct = sum(y_pred == y_test_fold)
accuracy = n_correct / len(y_pred)
print(accuracy)
위 처럼 직접 코드로 구현을 할 수도 있지만 Sciki-Learn 라이브러리를 활용해서 구할 수도 있습니다.
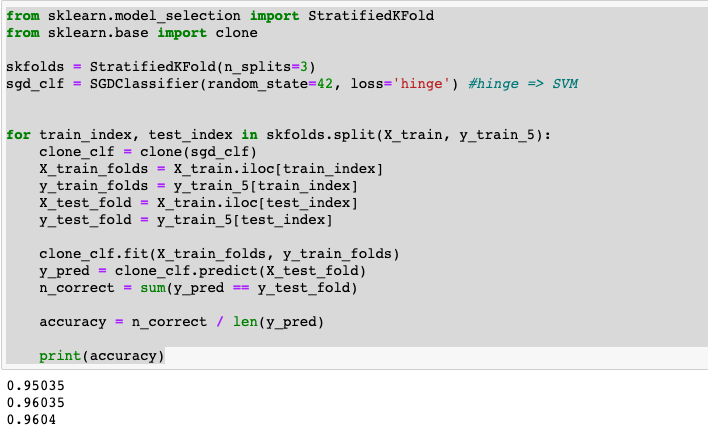
결과를 확인해봤을 때, 3 fold에서 모두 95% 이상의 정확도를 보였습니다. 굉장히 놀라운 수치죠. 시험 성적 100점 중에 95점을 맞은거니까요.
그런데 Classification에서는 중요한 것이 있습니다. 바로 class 별로 데이터를 구성하고 있는 비중입니다. 이진분류로 생각을 해보면 ‘예’라는 class가 전체 데이터 셋에서 90% 이상을 차지하면 모델이 그냥 ‘예’라는 결과만 내놓아도 정확도가 95%가 됩니다. 이게 좋은 모델이라고 할 수 있을까요? 아니겠죠. 우리가 확인해봤던 MNIST 이진분류 문제는 어떤지 확인해보겠습니다.
우선 전부 ‘5가 아니오’라는 대답을 내놓은 모델을 만듭니다.
from sklearn.base import BaseEstimator
class Never5Classifier(BaseEstimator):
def fit(self, X, y=None):
pass
def predict(self, X):
return np.zeros((len(X), 1), dtype=bool) # 데이터 길이 만큼 False를 리턴
아래 그림과 같이 정확도가 모든 fold에서 90% 나오는 것을 볼 수 있죠. 이는 5가 전체 데이터 셋에서 10%만 차지하기 때문에 모든 문제에 대해서 5가 아니라고 해도 성능이 90%나 나온 것입니다. 위에서 지적했던 문제가 있는 것이죠.

정확도에는 이러한 문제가 있으니 그럼 새로운 방식으로 모델을 평가하는 것이 필요합니다.
Confusion Matrix
Confusion Matrix는 하나의 도표인데요, Classifier 모델이 각 class별로 데이터를 어떻게 예측을 했는지에 대한 정보를 담고 있습니다
위의 선형 모델을 통한 결과를 보고 자세히 알아보죠.
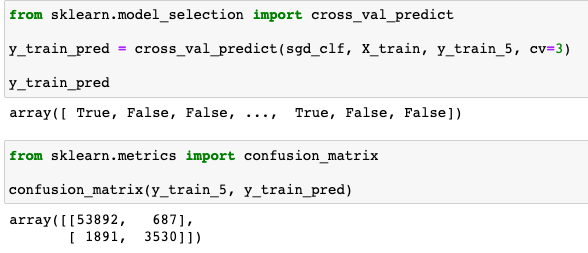
이번에도 Scikit-Learn에서 제공해주는 라이브러리를 통해 Confusion Matrix 만들어봤습니다.
결과를 하나의 표라고 봤을 때, 대각선에 위치한 수는 모델이 각 클래스에 맞게 데이터를 잘 예측한 것을 나타냅니다. 5인 이미지를 5라고 예측한 경우가 3,530, 5가 아닌 이미지를 5가 아니라고 예측한 경우가 53,892 입니다. 여기서 우리의 목표는 5인 이미지를 찾는 것이죠. 그렇기 때문에 5인 이미지는 positive class, 5가 아닌 이미지는 negative class가 됩니다. 모델이 잘 맞췄다면 true, 틀렸다면 false로 나타냅니다. 그렇다면 3,530은 모델이 5인 이미지를 잘 맞춘 것이기 떄문에 true positive인 경우의 수고 53,892는 true negative가 되겠습니다.
그럼 대각선을 제외한 나머지를 확인해볼까요. 687은 5가 아닌데 5라고 예측을 한 것이고, 1,891은 5인데 5가 아니라고 예측한 것이죠. 각각 false positive, false negative가 되겠습니다. (TP: true-positive, FP: false-positive, FN: false-negative, TN: true-negative)
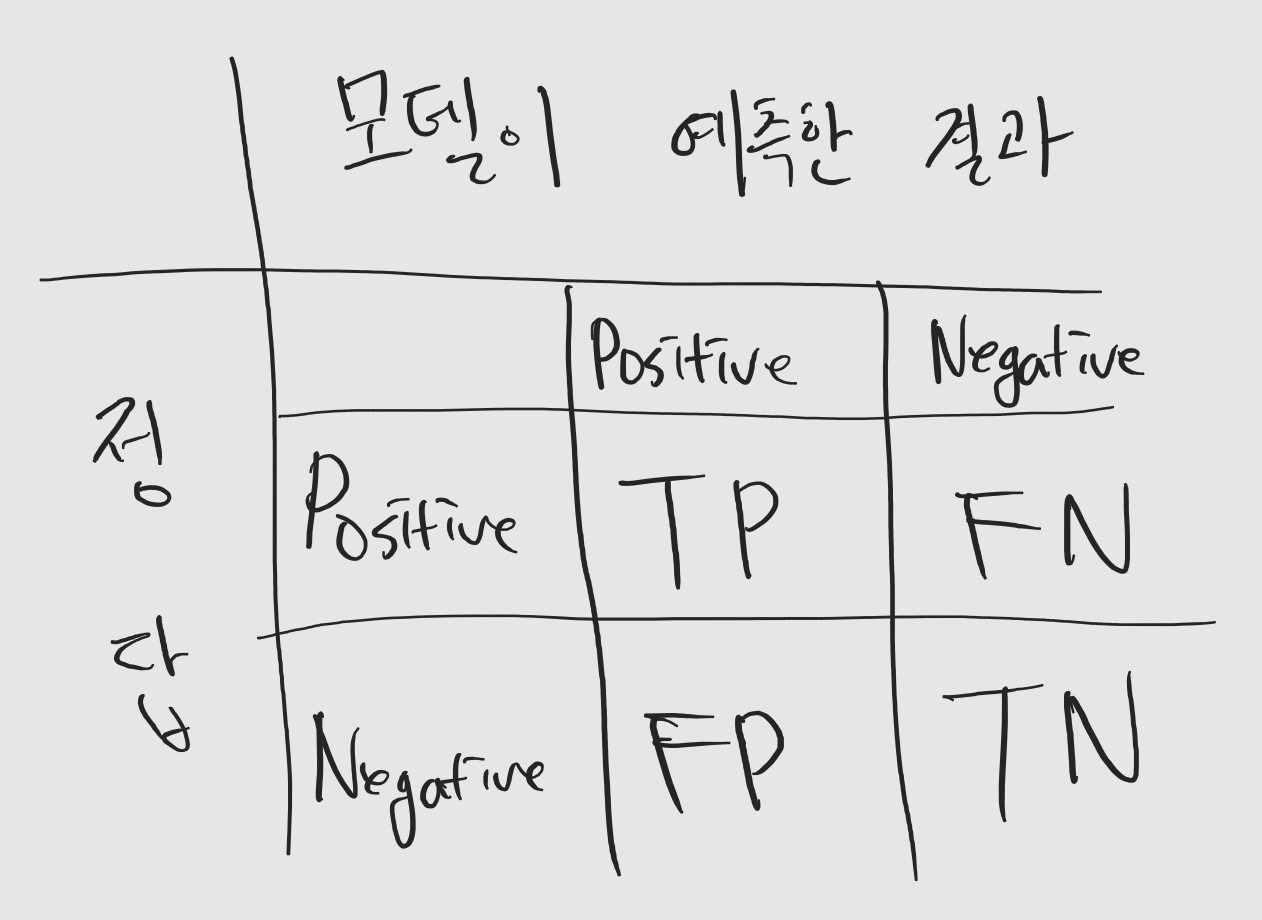
위에서 확인해봤던 정확도를 식으로 표현해보겠습니다.
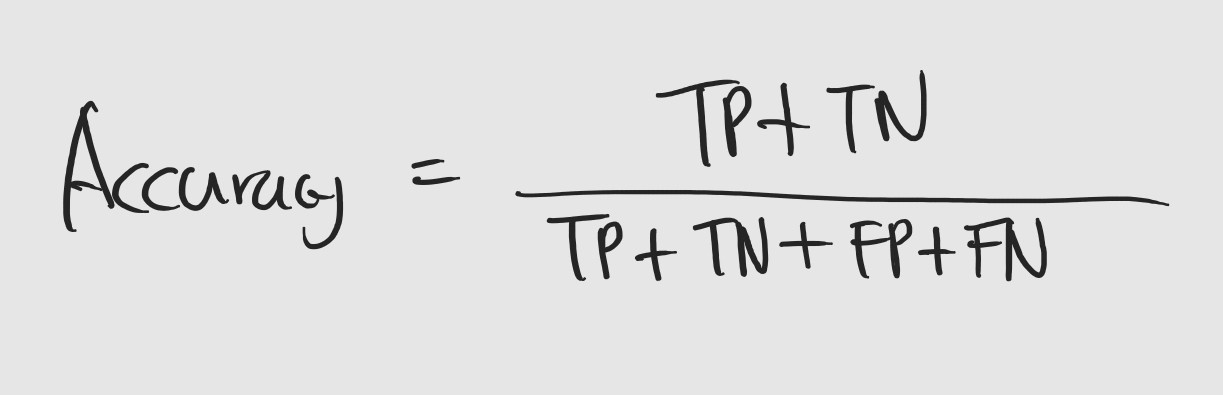
정확도 이외의 모델의 성능을 측정하는 지표가 어떤 것들이 있는지 알아보겠습니다.
- Precision
말 그대로 정밀도 입니다. 모델이 positive라고 예측한 것 중에 실제 positive의 비율을 의미합니다. 예를 들어보면, 모델이 5라고 예측한 것들 중에, 실제 5인 것의 비율을 의미합니다.
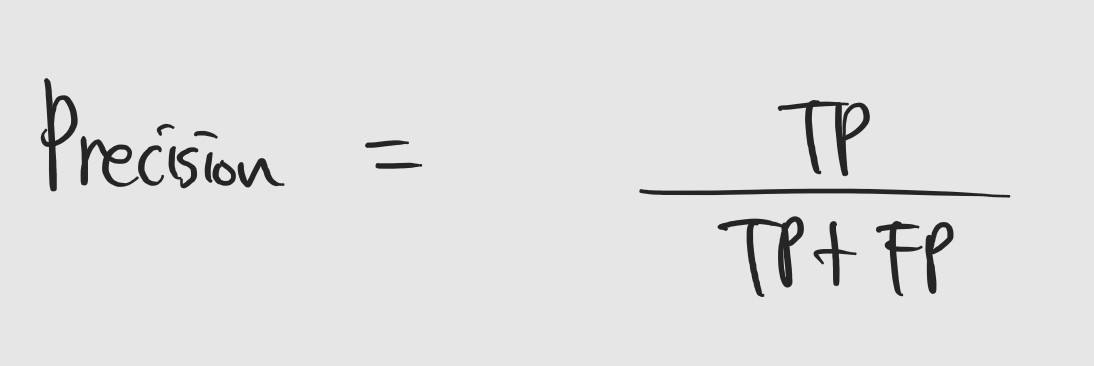
- Recall
재현율로, 실제 positive 중에 모델이 positive라고 예측한 것의 비율입니다. 예를 들어보면, 실제 5인 데이터 중에 모델이 5라고 맞춘 것의 비율을 의미합니다. Recall은 정확도가 문제가 되는 상황에 적합한 성능 지표라고 할 수 있는데요. Negative의 비율이 압도적으로 높을 때, 모델이 Positive인 것도 Negative라고 예측하면 Recall은 매우 낮아지게 되겠죠.
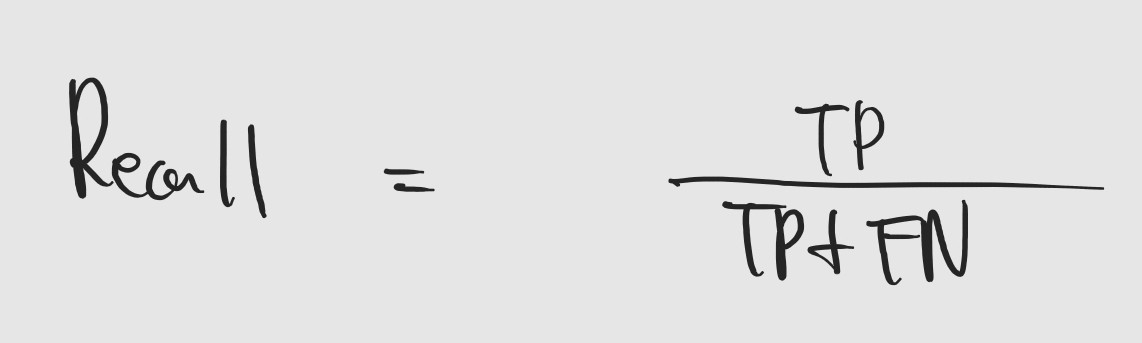
실제 위의 모델로 Precision과 Recall 지표를 확인해보겠습니다. 정확도와는 다른 양상을 보이는 것을 확인할 수 있습니다.

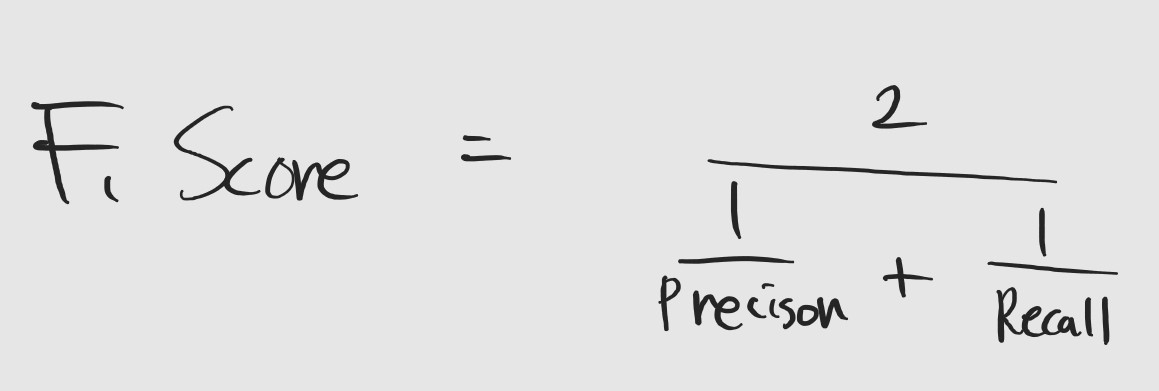
- F-1 score
F-1 score는 Precision과 Recall의 조화 평균입니다. Precision과 Recall은 수식을 보면 알겠지만, 서로 trade-off 관계에 있고 상황에 따라 활용될 수 있는 경우도 다르기 때문에 적절한 활용이 요구됩니다. 하지만, 매번 어떤 것이 좋은 지 확인하는 것은 번거롭겠죠. 그래서 Precision과 Recall의 장점을 조화롭게 활용한 성능 지표로 F-1 score가 나왔다고 볼 수 있습니다. 이런 때문에 분류 문제에서 정확도를 넘어서 가장 자주 사용하는 지표가 아닐까 생각이 듭니다.
MultiClass Classification
지금까지 Binary Classification에 대해서 살펴보았습니다. 지금부터는 다중 클래스를 분류하는 법을 확인해보겠습니다. 어렵지 않습니다. 이진분류를 위한 데이터 대신 원래 MNIST 데이터셋을 활용하면 됩니다.
위의 SGD 모델을 훈련해서 MultiClass Classification을 진행해보겠습니다.
sgd_clf = SGDClassifier(random_state=42, loss='hinge') #hinge => SVM
sgd_clf.fit(X_train, y_train)
첫번째 데이터에 대해서 Binary에서는 False/True로 결과가 나온거에 반해 3으로 특정 숫자로 결과가 나온 것을 확인할 수 있습니다.
Multiclass에 대해서도 Confusion Matrix를 확인해보고 heating map으로 시각화해보겠습니다.
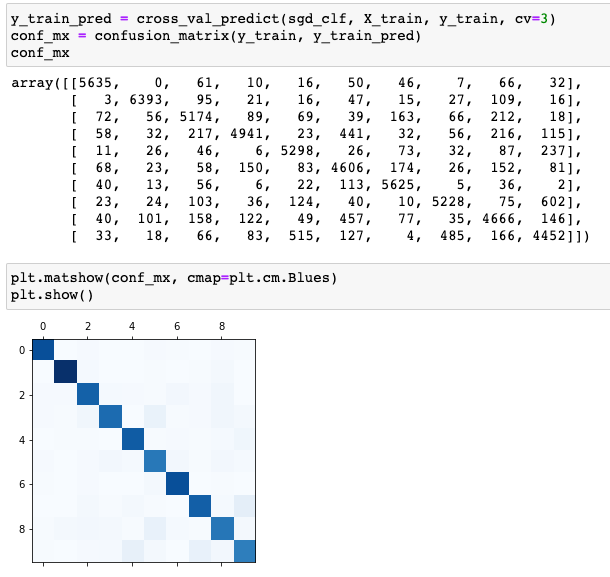
Binary에 비해 class가 많다보니 훨씬 보기 까다롭죠. 대신에 heating map을 보면서 어느 정도 추이를 확인해볼 수 있습니다.
heating map을 보면 전반적으로 모든 클래스에 대해 올바른 판단을 했지만 3,7,8,9에 대해서 다른 숫자들과 모델이 헷갈려 하는 것을 볼 수 있죠.
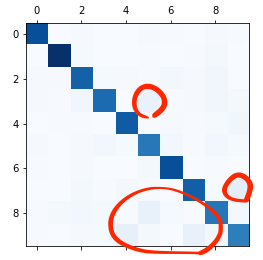
이것을 바탕으로 헷갈리는 이유가 무엇인지 분석을 하게됩니다. 이를 Error Analysis라고 합니다.
지금까지 머신러닝 task 중 Classification에 대해서 알아봤습니다. 다음 포스트는 모델 Training에 대해서 자세히 다룰 예정입니다.
댓글남기기