
머신러닝(Machine Learning) 이란? - 정의, 유형, 기본 지식
본 포스트는 머신러닝에 대한 정의와 머신러닝을 이해하는 데에 필요한 기본 지식에 대해 소개하는 글입니다.
1. 머신러닝(Machine Learning) 이란?
최근 들어, 가장 핫하고 주목받는 기술이 무엇이냐고 물어봤을 때, 대부분의 사람들이 아마도 인공지능 A.I. (Artificial Intelligence)라고 말할 겁니다. 기본적으로 인공지능은 사람이 하는 일이나 어떤 메커니즘을 기계가 대신 할 수 있는 기술을 의미하는데, 머신러닝(기계학습)은 인공지능을 구현하는 하나의 방법이다. 말 그대로, 기계를 사람처럼 행동하도록 학습 시키는 것이죠. 머신러닝이라고 했을 때, 대부분의 보통 사람들은 판타지 영화에 나오는 굉장히 대단하고 화려한 기술이라고 생각하지만 자동 스팸 필터링, OCR(Optical Character Recognition), SNS 얼굴인식 등 이미 다양한 서비스에 많이 활용되고 있고 쉽게 접할 수 있습니다.
그렇다면, 머신러닝은 무엇일까요? 머신러닝은 앞서 말한 것 처럼, 인공지능을 구현하는 하나의 방법으로 기존 프로그래밍 처럼 시스템에 특정 규칙을 미리 정의하는 것이 아닌 데이터를 통해 그 규칙을 학습하는 것을 의미합니다. 쉽게 말해서 시스템으로 하여금 기존 데이터를 보고 어떤 의사결정을 내릴 수 있도록 특정 규칙을 만들어 가는 것이라고 생각하면 됩니다.
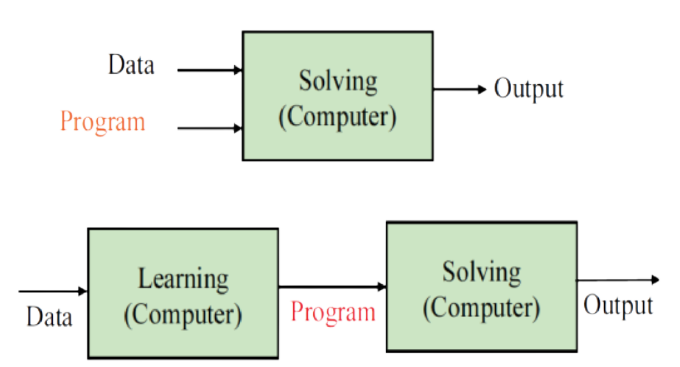 출처: "https://bi.snu.ac.kr/~scai/Courses/ML2017/ch1.pdf"
출처: "https://bi.snu.ac.kr/~scai/Courses/ML2017/ch1.pdf"
위의 첫번째 그림은 머신러닝이 아닌 일반적인 컴퓨터 프로그램을 나타낸다. 미리 짜여진 프로그램에 입력 데이터를 넣었을 때, 원하는 결과물을 얻을 수 있습니다. 이와 달리, 두번째 그림처럼 훈련용 데이터 (training data)를 기반으로 그에 맞게 훈련된 모델 또는 프로그램이 결과물이 되는 것이 기본적인 머신러닝의 concept이라고 할 수 있습니다. 예를 들어, 스팸 메일을 필터링하는 머신러닝 모델을 만들고 싶다고 했을 때, 스팸 메일과 스팸이 아닌 메일로 구성된 데이터셋을 통해 모델이 스팸 메일 만의 특징 및 패턴을 찾아내도록 훈련이 되는 것입니다.
2. 머신러닝의 장점.
이러한 머신러닝의 장점은 사람이 스팸 메일의 모든 특징 및 패턴을 찾아내기 힘들 뿐더러 프로그램 자체가 매우 복잡해질 가능성이 높고 새롭게 생길 수 있는 특징 및 패턴에 대해서 유지보수가 까다로울 가능성이 높습니다. 이에 반해, 머신러닝 모델은 수집된 데이터를 통해 모델을 계속 훈련 시켜주기만 하면 되기 때문에 프로그램 자체는 간단하고 유지보수가 용이하고 더 정확하다는 장점이 있습니다.
여기서 포인트는 데이터에 맞게 모델이 알아서 훈련이 된다는 것입이다. 처음 머신러닝을 접하는 사람은 이 개념을 먼저 이해하고 받아들이는 것이 힘들지만 가장 중요한 개념이라고 할 수 있습니다.
3. 머신러닝의 유형.
머신러닝의 유형은 어떤 기준으로 하느냐에 따라 다양한 유형으로 분류할 수 있다. 이 글에서는 대표적으로 학습 방법 (supervision) 에 따른 유형을 소개하려고 합니다.
- 지도학습 (Supervised Learning).
Supervised Learning은 입력 데이터를 통해 특정 결과를 예측하도록 모델을 훈련하는 방식을 의미합니다. 대표적으로, 사진을 보고 강아지인지 고양이인지 분류하는 등의 Classification task, 주식을 예측하는 등의 Regression task를 예로 들 수 있습니다. 이런 task들을 훈련하기 위해서는 데이터 별로 정답이 주어져야 한다. 따라서, Supervised Learning을 위한 훈련 데이터 셋에는 label이라고 불리는 정답이 포함되어 있습니다. 여기서 포인트는 Supervised Learning은 훈련 데이터에 label이 포함되어 있다는 것입니다.
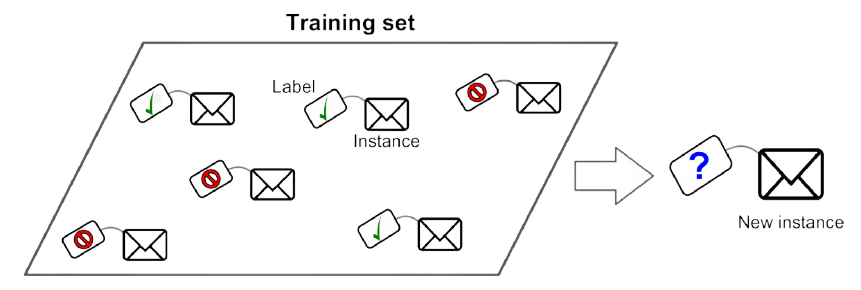 출처: Hands-on Machine Learning with Scikit-Learn, Keras & TensorFlow 2nd Edition
출처: Hands-on Machine Learning with Scikit-Learn, Keras & TensorFlow 2nd Edition
- 비지도학습 (Unsupervised Learning).
Unsupervised Learning은 Supervised Learning과 다르게 데이터 셋에 label이 포함되어 있지 않습니다. 따라서 Unsupervised Learning은 어떤 특정 결과를 예측하는 방식이 아니라 데이터 만의 특징이나 패턴을 찾아내는 방식이라고 할 수 있습니다. 예를 들어, 특정 기준에 따라 데이터를 그룹화하는 Clustering, 고차원의 데이터를 저차원으로 표현하는 Dimension Reduction이 있습니다. 여기서 포인트는 Unsupervised Learning은 label이 없고 데이터의 특징이나 패턴을 찾아내는 훈련 방식이다는 것입이다.
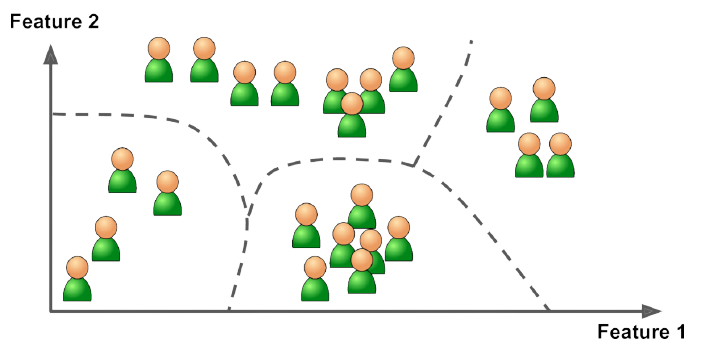 출처: Hands-on Machine Learning with Scikit-Learn, Keras & TensorFlow 2nd Edition
출처: Hands-on Machine Learning with Scikit-Learn, Keras & TensorFlow 2nd Edition
- 준지도 학습 (Semisupervised Learning).
Semisupervised Learning은 위의 두 가지 유형이 특징을 모두 갖고 있습니다. 쉽게 말해, 데이터 중 일부 만이 label을 가지고 있다는 것입이다. Unsupervised Learning 방식으로 데이터의 특징 및 패턴을 찾아낸 후, Supervised Learning 방식으로 특정 결과를 예측하는 방식을 예로 들 수 있습니다.
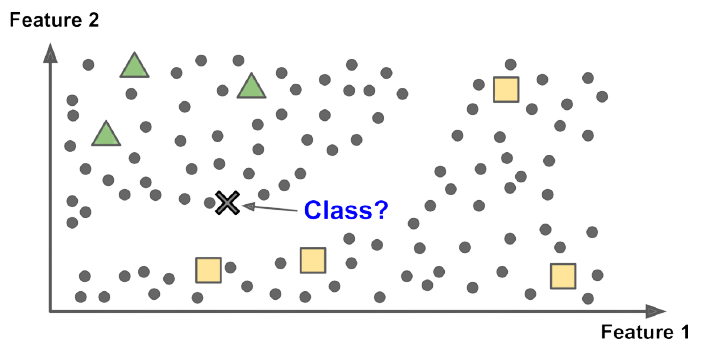 출처: Hands-on Machine Learning with Scikit-Learn, Keras & TensorFlow 2nd Edition
출처: Hands-on Machine Learning with Scikit-Learn, Keras & TensorFlow 2nd Edition
- 강화 학습 (Reinforcement Learning).
Reinforcement Learning은 학습되는 시스템을 Agent라고 부릅니다. 이 agent가 주변 환경 environment를 관찰하며 적절한 행동 action을 취하게 되고 그에 맞는 보상 reward를 받게 됩니다. 보상은 말 그대로 보상일 수도 있고 penalty일 수도 있습니다. agent는 이런 보상에 따라서 환경 environment에 따른 행동 action을 학습하게 됩니다. 예를 들어, 알파고가 있는데 시스템 agent는 바둑판에 놓여진 바둑 알의 패턴 environment를 확인하고 바둑알을 놓는데 action, 바둑의 승패 reward에 따라 agent가 environment에 따른 적절한 action을 취하도록 훈련됩니다.
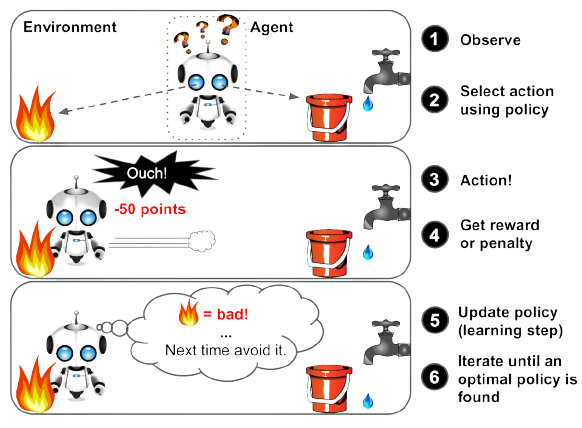
출처: Hands-on Machine Learning with Scikit-Learn, Keras & TensorFlow 2nd Edition
앞으로 여러 머신러닝 알고리즘을 자세히 살펴 보면서 위 유형들의 특징을 명확히 할 예정입니다.
4. 머신러닝의 한계.
여러가지 머신러닝 알고리즘이 개발되고 사용되고 있지만, 1. 데이터 측면, 2. 알고리즘 측면 두 가지 측면에서 한계가 존재합니다.
데이터 측면
좋은 머신러닝 모델을 완성하는 데 있어서, 데이터의 역할은 매우 중요합니다. 어쩌면 알고리즘을 어떻게 짜는 지 보다 더, 훈련 데이터의 양과 질이 모델의 성능에 더 큰 영향을 끼치기도 합니다. 데이터에 문제가 있으면 당연히 머신러닝 모델의 성능에 영향을 끼치기 마련입니다.
- Insufficient Quantity of Training Data
일반적으로 머신러닝 모델을 학습시키기 위해선, 아무리 쉬운 문제를 풀기 위한 모델이여도 굉장히 많은 양의 데이터가 필요합니다. 따라서, 모델을 훈련시키기에 데이터의 양이 충분하지 않다면 문제가 생길 수 있습니다. - Nonrepresentative Training Data 머신러닝의 가장 큰 목표 중 하나는 Generalization, 즉 일반화 인데요. 훈련된 모델이 새로운 데이터에 대해서도 잘 동작해야 한다는 것이죠. 예를 들어, 강아지와 고양이를 구분하도록 훈련된 모델이 훈련 데이터 셋에 없는 사진에 대해서도 잘 구분을 해야하는 것입니다. 그런데 만약 훈련 데이터 셋이 일반적인 특성이나 패턴을 담고 있지 못한다면 어떡해 될까요? 일반화가 안 될 것입니다. 따라서, 일반화를 위해 적절한 데이터 샘플링이 매우 중요합니다.
- Poor-Quality Data Outlier, Error, Noise 등의 일반적이지 않은 특징을 지니고 있는 데이터들로 훈련한다면, 데이터의 양이 많다고 해도 나쁜 영향을 끼칠 것입니다. 따라서, 훈련 전 데이터 분석을 통해 이러한 데이터를 제거하여 품질을 높이는 것이 매우 중요합니다.
- Irrelevant Features 데이터가 가지고 있는 feature들 중, 실제 모델이 동작할 때 필요한 feature는 그 중 일부일 수 있습니다. 때문에 나머지 불필요한 feature들은 오히려 계산량만 늘릴 뿐, 쓸모가 없는 것이죠. 훈련 전에 불필요한 feature를 제거(feature selection)하거나 감소 시키는 것(feature extraction)이 필요합니다. 이를 feature engineering이라고 부릅니다.
모델 (알고리즘) 측면
모델을 어떻게 구성하는 지, 또는 어떻게 훈련 시키는 지도 모델의 성능에 많은 영향을 끼칩니다.
-
Overfitting
Overfitting은 말 그대로, 모델이 훈련 데이터 셋에만 좋은 성능을 보이도록 과하게 훈련되었다는 것이죠. 이렇게 된다면 앞서 말했던, 일반화가 어려워질 수 있습니다. 오버피팅의 원인은 크게 두 가지로 들 수 있는데요. 하나는 데이터의 양이 적을 때, 다른 하나는 모델이 너무 복잡할 때 입니다. 모델이 복잡하면 세밀한 패턴이나 특징까지 잡아낼 수 있다는 장점이 있습니다. 하지만 그것을 데이터가 매우 이상적일 때(Noise, Outlier가 없고 일반화가 잘 되도록 샘플링 된), 이야기 입니다. 사실상 그것은 불가능에 가까운 것이죠. 때문에 모델이 훈련 데이터 셋에 과적합(overfitting) 될 정도로 복잡하다면 앞서 설명한 것 처럼 일반화에 큰 어려움이 생길 것입니다. 따라서 이런 과적합 문제를 해결하려는 시도가 많이 제안되어 왔습니다. 정규화 같이 모델의 복잡도를 낮추려는 것이 대표적인 예입니다. -
Underfitting
말 그대로 오버피팅의 반대라고 할 수 있습니다. 모델이 너무 단순하여 훈련이 안된다는 것이죠. 이것을 해결하는 방법은 모델을 더 복잡하게 만드는 것입니다.
5. 모델의 성능 평가 및 조정
Testing and Validating
모델이 일반화가 잘 되었는지 확인하기 위해서는 훈련 데이터 셋에 존재하지 않은 데이터를 통해 성능을 평가해야 합니다. 이를 위해서, 가지고 있는 데이터를 모두 훈련에 활용하는 것이 아닌 일부를 테스트 용 데이터로 활용하는 것입니다. 일반적으로 8:2 비율로 8은 훈련 용, 2는 테스트 용으로 활용합니다. 성능 평가는 훈련 성능과 테스트 성능을 따로 측정을 하게 되는데요, 훈련의 성능은 매우 좋은데 테스트 성능은 좋지 않다면 이것을 모델이 훈련 데이터 셋에 오버피팅 되었다고 합니다. 이처럼, 훈련 성능과 테스트 성능을 통해 모델의 일반화 성능을 판단합니다. 모델이 훈련 데이터 셋에 과적합되는 것을 방지하기 위해, 훈련을 일찍 끝내기도 하는데 이것을 early stopping이라고 합니다. 이는 추후에 자세히 다루도록 하겠습니다.
Hyperparameter Turning & Model Selection
모델을 구성하고 있는 변수를 보통 ‘parameter’라고 표현을 한다. 여기에는 학습을 통해 update되는 weight 가중치와 학습 전 사용자에 의해 미리 그 값이 정의되는 hyperparameter 하이퍼파라미터가 있습니다. learning rate가 대표적인 예 입니다. 하이퍼파라미터를 적절하게 설정하는 것도 모델의 성능에 영향을 끼칠 수 있습니다. 적절한 하이퍼파라미터를 설정하는 방법은 다양한 시나리오로 실험을 하는 수 밖에 없습니다. 이를 위해, validation 데이터 셋을 도입하기도 하는데요. 실제로 테스트 데이텉 셋으로 성능을 평가하기 전에 훈련 데이터 셋의 일부로 성능을 평가하는 것입니다. 이를 통해, 가정 적절한 하이퍼파라미터를 설정하고 모델을 선택하게 되는 것입니다.
지금까지, 머신러닝의 정의와 기본적인 내용에 대해서 살펴보았습니다. 다음 포스트에서는 데이터 분석 부터 모델 훈련 및 검증까지 머신러닝의 전반적인 pipeline에 대해서 다룰 예정입니다. 그 이후, 본격적으로 머신러닝의 여러 알고리즘 및 알아야할 개념들에 대해서 자세히 다룰 에정입니다.
댓글남기기