
머신러닝 프로젝트 파이프라인(1)
이번 포스트는 머신러닝 프로젝트가 어떤 과정을 거쳐 진행이 되는지 기본적인 프로세스 및 파이프 라인에 대해서 소개하려고 합니다. 기본적으로 머신러닝 프로젝트는 가설을 세우는 것부터 데이터를 수집 및 처리, 모델 설계 및 성능 평가까지 여러 단계를 거쳐서 진행이 되는데요. 대략적으로 머신러닝 모델을 개발하는 데에는
- 데이터 수집 및 분석
- 데이터 전처리 및 피처 추출
- 모델링
- 학습
- 검증
크게 5가지 단계가 필요합니다. 먼저 해결하고자 하는 문제에 관련된 데이터를 수집을 하고 이를 분석하여 모델에 대한 컨셉을 잡은 다음 이에 맞게 데이터를 전처리하고 중요한 피처를 추출합니다. 이처럼 모델과 데이터 셋을 구축하면 본격적으로 모델을 준비된 데이터 셋으로 훈련을 시킵니다. 훈련된 모델을 테스트 데이터 셋으로 검증으로 하고 다시 훈련을 시키고 다시 검증하고 이런 과정을 반복하는 것이지요. 실제 핸즈온머신러닝에 나와있는 the California Housing Prices dataset의 간단한 프로젝트를 예시로 해서 각각의 단계에 대해서 자세하게 알아보겠습니다.
- the California Housing Prices dataset: 미국 캘리포니아 주의 구역 별 집값에 대한 통계자료로 구역 별 인구 수, 수입에 대한 정보가 함께 주어진다.
1. Look at the big picture
이 과정은 본격적으로 머신러닝 모델을 개발하기 전, 전반적인 프로젝트를 계획하고 준비하는 단계 그리고 어떤 컨셉으로 모델을 개발할 지 분석하는 단계라고 볼 수 있습니다.
Frame the Problem
말 그대로 문제 상황을 명확하게 하는 것입이다. 모든 프로젝트와 마찬가지로 머신러닝 프로젝트도 프로젝트의 목표가 무엇인지 어떤 문제를 해결하기 위해서 모델을 개발하는 지에 대해 명확히 하는 것부터 시작하는 것이죠. 저번 포스트에서 설명했던 어떤 유형의 머신러닝 프로젝트인지; supervised, unsupervised 또는 reinforcement, 큰 틀을 먼저 정해야합니다. 여기서는 the California Housing Prices dataset을 가지고 집 값을 예측하는 프로젝트를 진행하기 때문에 집 값이라는 결과를 도출해야겠죠. 따라서 supervised 유형을 선택해야합니다.
이외에도 해당 문제에 대한 기존 해결 방법에 대해서 조사를 해야 합니다. 기존 방법을 분석하다 보면 그것이 가지고 있는 문제점이나 한계를 발견할 수 있고 이것은 실제 아이디어를 얻고 모델링을 하는 데에 도움이 될 수 있습니다.
Select a Performance Measure
다음은 실제로 모델을 개발했을 때, 모델이 동작을 잘 하는지 평가하기 위한 지표를 선택해야합니다. 예를 들어, regression task에 대한 지표로는 Root Mean Square Error(RMSE)를 많이 활용합니다. 사실 이런 평가 Metric을 정하는 것은 각 task별로 많이 활용되는 것은 선택하는 경우가 대부분일 것입니다. 그래서 프로젝트를 진행하기 전 따로 평가 Metric을 정한다기 보다는 하고자하는 task 또는 dataset을 정한다면 이는 자연스럽게 정해지는 부분이지 않을까 생각이 드네요. 이렇게 고착화된(?) 이유를 생각해보자면 아마도 기존 모델과의 성능을 비교해야하기 때문이지 않을까하는 생각이 듭니다. 그렇다고 해서 꼭 기존 평가 Metric을 활용해야한다는 것은 아닙니다.
Check the Assumptions
마지막으로 이 단계에서는 위의 과정을 통해 제안된 가정들과 발견들을 나열한 다음, 최종적으로 프로젝트의 방향성과 컨셉을 정합니다.
2. Get the Data
이 과정은 실제로 데이터를 수집하고 또는 기존 공개된 데이터를 가져와서 데이터가 어떤 식으로 이루어져 있고 어떤 특징을 가지고 있는 지 확인하는 단계라고 볼 수 있습니다. 실제로 jupyer notebook을 활용해 the California Housing Prices dataset을 가져와서 데이터를 확인해보겠습니다. 본 포스트에서 활용한 코드는 github에서 확인하실 수 있습니다.
아래 코드의 fetch_housing_data 함수를 통해 통해 California Housing Prices 데이터 셋을 가져옵니다. 아래 함수를 실행하면 datasets/housing 디렉토리에 housing.cvs 파일이 생성되는 것을 확인할 수 있습니다.
# Fetch Function of the California Housing Prices Dataset
import os
import tarfile
import urllib
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml2/master/"
HOUSING_PATH = os.path.join("dataset", "housing")
HOUSING_URL = DOWNLOAD_ROOT + "datasets/housing/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH): #housing_path로 폴더생성해서 데이터셋 다운
os.makedirs(housing_path, exist_ok=True)
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path)
housing_tgz.close()
아래 코드는 csv 파일 형식의 데이터를 pandas의 DataFrame 형식으로 load하는 함수 코드입니다.
import pandas as pd
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path)
데이터를 load해서 몇개만 확인해보겠습니다아. DataFrame의 head() 함수를 통해 데이터 상위 5개의 데이터만 출력해보겠습니다.
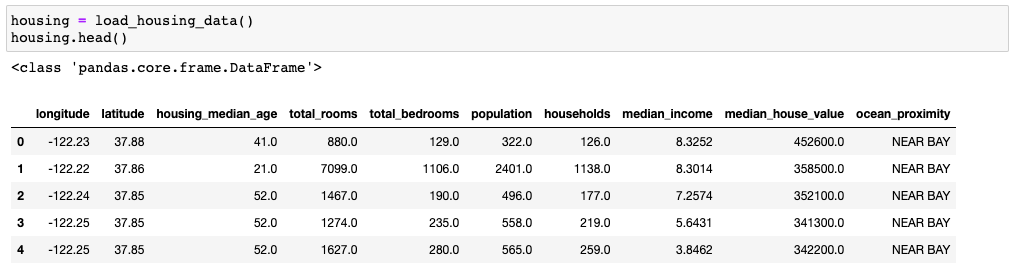
데이터는 각각 총 10개의 attribute 또는 feature 로 이루어진 것을 확인할 수 있습니다; longitude, latitude, housing_median_age, total_rooms, total_bedrooms, population, households, median_income, median_house_value, ocean_proximity
그 다음은 데이터의 attribute 별로 데이터 타입이 무엇인지, NULL 값에 대한 정보 등에 대해서 확인해보겠습니다.
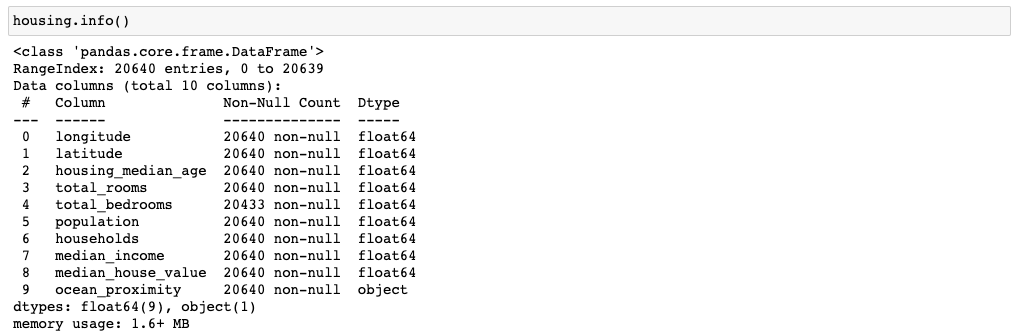
여기서 주목해야할 점은 total_bedrooms의 non-null 데이터가 다른 attribute 와는 다르게 20,433개 인 것을 확인할 수 있습니다. 이는 추후에 데이터 전처리하거나 피처 추출할 때, 처리를 해줘야하는 부분이라고 생각할 수 있겠죠. 이는 추후에 다시 확인해보겠습니다.
그 다음은 attribute 별로 데이터의 특징을 알아볼텐데요, 이는 numeric한 attribute와 categorical attribute 각각 다르게 확인할 수 있습니다. 먼저 categorical인 ocean_proximity를 살펴보겠습니다.

카테고리 별로 몇 개의 데이터가 존재하는지 확인할 수 있습니다.
그 다음은 numerical attribute를 확인하는 방법입니다.
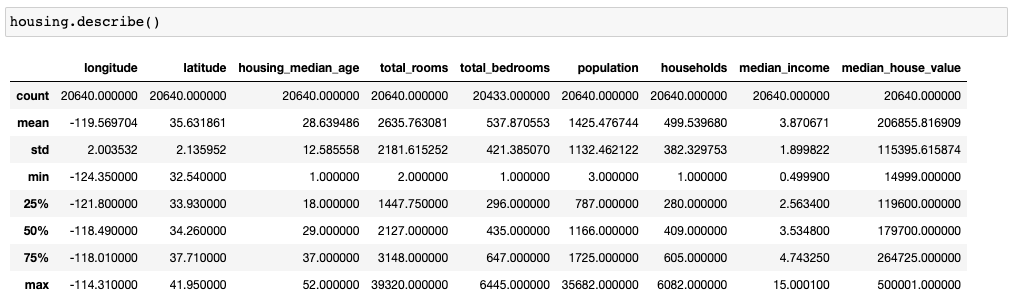
count는 데이터의 개수, mean은 평균 값, std는 분산, min은 최소 값, 25%, 50%, 75%는 각각 4분위수를 max는 최대 값을 의미합니다. attribute 별 기본적인 통계적 특징을 확인할 수 있습니다.
마지막으로 numerical attribute를 히스토그램 형태로 시각화하는 방법입니다.
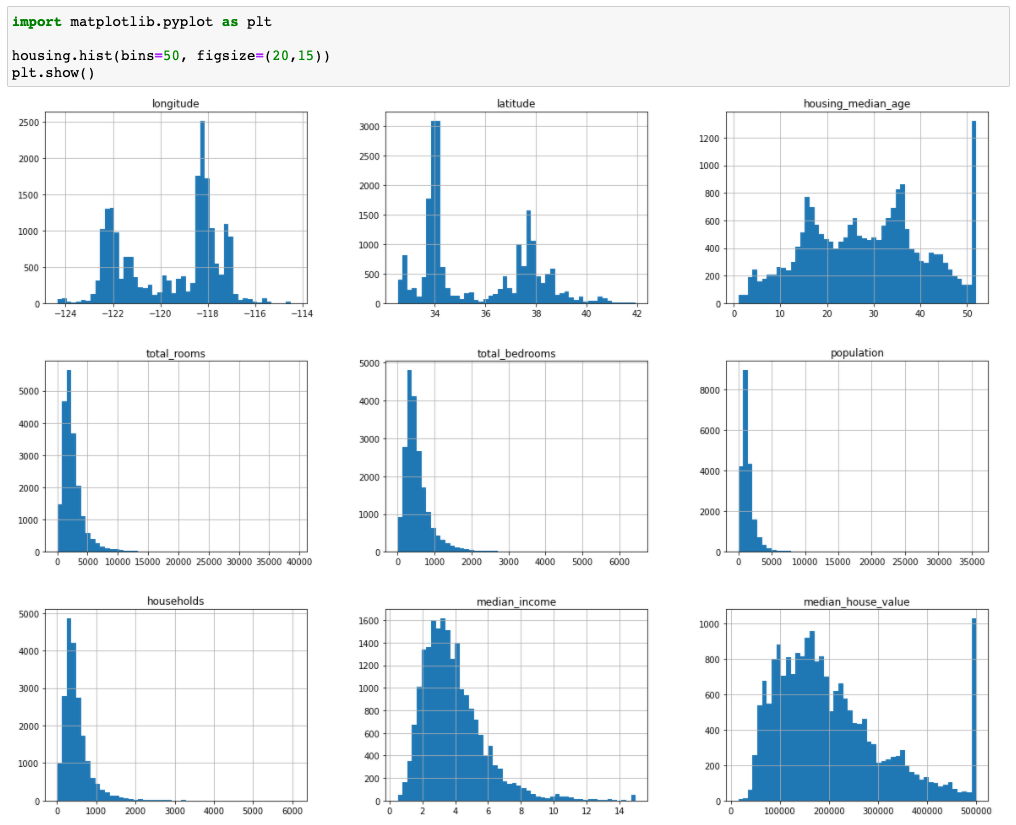
attribute 별로 데이터가 어떻게 분포되어있는지 확인할 수 있습니다. 여기서 확인해볼 수 있는 특징은 우리가 예측해야하는 median_house_value 값의 범위가 500000 이하로 한정되어 있는 것을 확인할 수 있습니다. 하지만 실제 데이터에는 범위 밖의 값이 있을 수 있기 때문에 이전 장에서 언급했던 일반화 측면에서 문제가 발생할 수 있습니다. 이를 어떻게 처리해야할 것이냐도 생각을 해야겠지요.
이상 머신러닝 파이프라인 중에서 데이터 수집까지 알아 봤습니다. 다음 장은 데이터를 훈련 데이터 셋과 테스트 데이터 셋으로 나누는 방법과 실제로 시각화를 통해 intuition을 얻는 과정에 대해서 설명하도록 하겠습니다.
댓글남기기