
머신러닝 프로젝트 파이프라인(2)
이번 포스트에서는 저번 포스트에 이어 머신러닝의 기본적인 프로세스 및 파이프 라인 중에서도 데이터를 훈련 데이터 셋과 테스트 데이터 셋으로 나누는 방법과 실제로 시각화를 통해 intuition을 얻는 과정에 대한 내용을 다루고자 합니다.
Create a Test Set
데이터 셋은 크게 훈련용 데이터셋 (train_set)과 검증용 데이터셋 (test_dataset)으로 나눌 수 있습니다. train_set은 말 그대로 모델을 훈련시킬 때, test_set은 훈련된 모델을 평가할 때 활용하는 데이터 셋입니다. 보통 데이터를 나눌 때 고려해야 할 점은 비율과 편향성 (bias) 입니다.
비율
train set과 test set의 비율은 보통 8:2 혹은 7:3을 많이 선택을 합니다. 경험상 validation_set의 여부에 따라서 달라진다고 생각을 하는데, validation 단계를 적용할 때, 주로 8:2를 선택하는 경향이 있는 것 같습니다. 선택한 비율로 데이터셋을 나누기 전에 명심해될 것은 train set과 test set은 일관되게 고정되어야 한다는 것입니다. 그렇지 않다면 모델이 훈련 단계를 거듭하면서 모든 데이터에 대해서 훈련이 진행될 것이고 성능 검증을 하는 것이 무의미하게 되겠죠. 따라서, 특정 dataset의 train/test set은 fix되어야 합니다. 생각해보면 그래야지 다른 모델 또는 연구들과 성능을 비교할 수 있겠죠.
import numpy as np
def split_train_test(data, test_ratio):
shuffled_indices = np.random.permutation(len(data))
test_set_size = int(len(data) * test_ratio)
test_indices = shuffled_indices[:test_set_size]
train_indices = shuffled_indices[test_set_size:]
return data.iloc[train_indices], data.iloc[test_indices]
위의 코드는 데이터의 index를 활용해 데이터 셋을 분리하는 함수입니다. 0부터 데이터 길이만큼 numpy array를 permutation 함수로 shuffle한 다음 test_ration 지점에서 나눈다음 거기에 해당하는 index의 데이터를 반환해주는 방식입니다.

train/test 개수가 각각 16512/4128 개로 나뉜 것을 확인할 수 있습니다. train set과 test set은 일관되게 고정하기 위해서 위 함수의 permutation이 동작학 전에 random seed를 일정한 값으로 선언해주어야 합니다. 이는 sklearn 라이브러리의 train_test_split 함수로 대체할 수 있습니다.
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42) #housing : data, test_size : test_ratio, random_state : random_seed

앞서 구현했던 split_train_test의 결과와 같은 것을 확인할 수 있습니다.
하지만 이런 방법들은 원래의 데이터 셋에 변화가 있을 경우 문제가 생길 수 있습니다. 예를 들어서, 데이터의 순서가 변경될 경우가 있겠죠. 데이터의 순서가 변경되면 index를 활용하는 방법을 통해서는 일관된 데이터 양상을 뽑아낼 수 없을 것입니다. 이를 해결하기 위해, 각 data 별로 고유한 id 혹은 hash 값을 뽑아내기도 하는데요, id는 있으면 데이터 셋에 명시가 되어있습니다. 만약 없다면 데이터 별로 hash 값을 구해야하는 데, 대부분 위의 방법으로도 충분하거나나 데이터별 id가 존재하는 경우가 대부분입니다.
편향성
데이터의 양이 매우 많다면 단순하게 위와 같이 random하게 데이터를 분리한다면 특정 데이터가 한쪽으로 편향되는 경향이 매우 적을 것입니다. 하지만, 데이터의 수가 충분하지 않을 경우 데이터 편향 문제가 발생할 수 있는데 이를 sampling bias라고 보통 칭합니다. 데이터의 특정 attribute의 클래스가 3개 있고 각각 0.4, 0.3, 0.3의 비율을 유지한다고 했을 때, train, test set에서 모두 비슷한 양상을 띄어야한다는 것이죠. housing data의 median_income attribute를 통해서 해당 과정을 알아보겠습니다.
먼저, median_income을 5개의 label로 카테고리화 시킵니다.
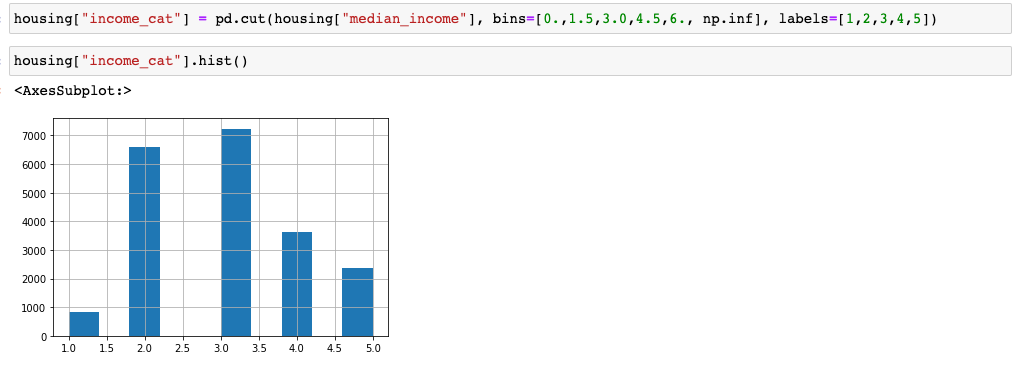
그 다음 sklearn의 StratifiedShuffleSplit을 통해 각 카테고리의 비율이 유지되면서 데이터를 분할하도록 하겠습니다.
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
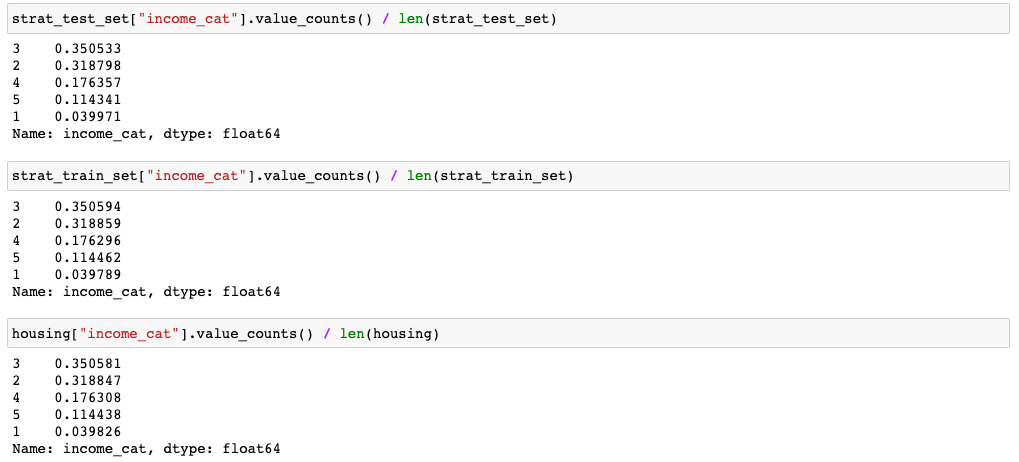
결과를 확인했을 때, train/test set 각각에서 카테고리 별로 비율이 원래 데이터의 비율과 비슷하게 유지되는 것을 확인할 수 있습니다. 지금까지 train/test set 분할하는 과정에 대해서 알아봤습니다.
Discover and Visualize the Data to Gain Insights
자, 지금까지 데이터의 전반적인 특징을 살펴보았는데요, 이제부터 데이터를 시각화해서 어떤 특성이 있는지 좀더 깊게 살펴보도록 하겠습니다. 이제 부터는 앞서 처리했던 train/test data 중에 train data만을 가지고 진행하도록 하겠습니다. 모델링 하는 데 있어서 test 데이터를 본다면 의미가 없는거겠죠! 그래서 먼저 train set을 이전에 쓰던 housing에 복사시켜줍니다. copy()를 통해 train set에 영향을 주지 않습니다.
housing = strat_train_set.copy()
먼저, latitude와 longitude의 지리적 정보를 통해 데이터를 시각화 해보겠습니다. 이 때, alpha 값을 1보다 작게 설정해서 데이터의 밀도가 높은 곳을 더 잘 확인할 수 있습니다. 확실히 특정 구역에 집이 몰려있는 것을 확인할 수 있습니다.
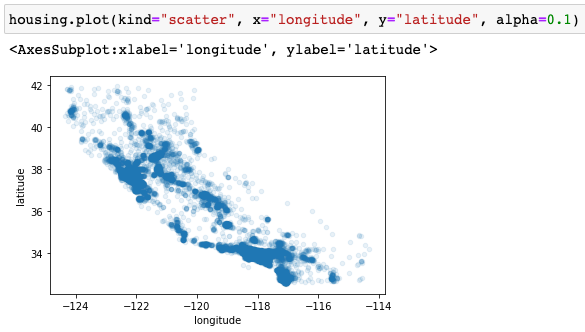
위의 그래프를 기반으로 housing price와 인구수를 그래프에 표현해보겠습니댜.
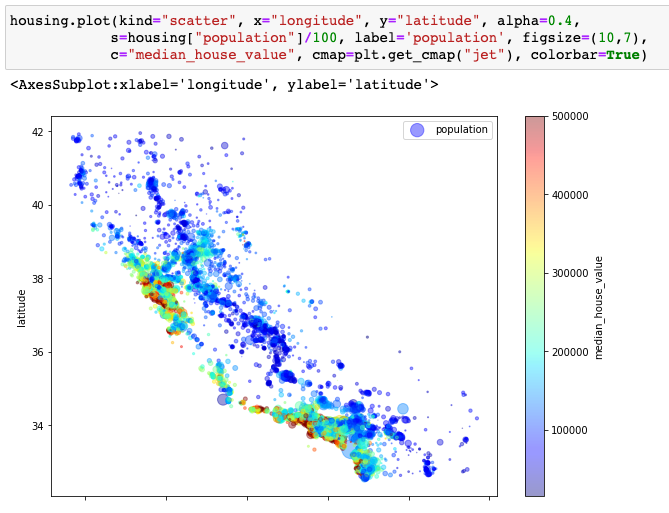
집이 몰려있는 곳에 인구 수도 많고 집 가격도 다른 곳에 비해 월등히 높은 것을 확인할 수 있습니다. 집의 위치와 인구 수가 집 가격과 높은 연관성이 있다는 intuition을 얻을 수 있습니다. 그럼 실제로 통계적 분석으로 확인해보겠습니다.
기본적으로 pearson 상관 계수를 구해서 attribute 별로 얼마나 집의 가격과 선형적으로 연관성이 있는지 확인해보겠습니다.
corr_matrix = housing.corr()
corr_matrix["median_house_value"].sort_values(ascending=False)
기본적으로 1 또는 -1에 가까울 수록 선형 연관성이 높다고 하고 0에 가까울 수록 선형적으로 연관성이 떨어진다고 볼 수 있습니다.
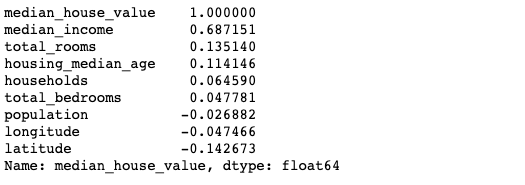
상관 계수를 봤을 때, median_income 수입이 집 값과 선형적으로 연관이 높은 것을 확인할 수 있습니다. 즉 수입이 높으면 비싼 집에 산다 혹은 비싼 집에 살면 수입 높다라는 intuition을 얻을 수 있습니다. 이에 반해, 위 그래프에서 연관이 높을 것이라고 생각했던 지리적 특성과 인구 수는 0에 가까운 모습을 보입니다. 하지만 상관계수는 선형적 관계 만을 보는 것이기 때문에 관련이 없다고 생각하는 것은 오산이죠. 때문에 통계적 분석과 시각적 분석 둘 중 하나만 하는 것이 아닌 두 가지 방법 모두 필요하다고 결론 내릴 수 있겠습니다.
주어진 attribute 바탕으로 새로운 attribute를 만들어 위의 방법을 적용하는 것도 하나의 방법입니다. 새롭게 rooms_per_household, bedrooms_per_room, population_per_householde를 만들어서 상관계수를 확인해보겠습니다.
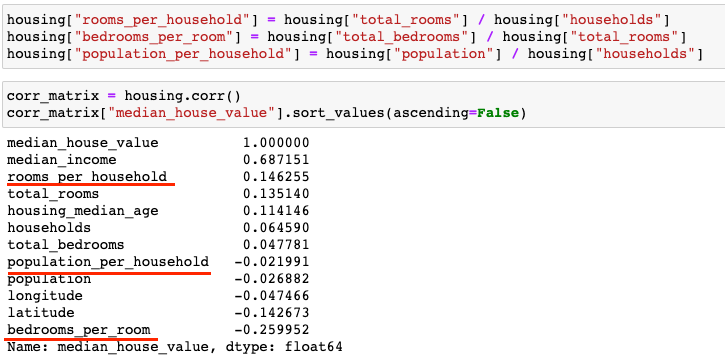
rooms_per_household, bedrooms_per_room는 기존의 attribute들 보다 더 높은 상관관계를 나타내는 것을 확인할 수 있습니다.
지금까지 데이터를 좀 더 깊게 살펴보고 intuition을 얻는 과정에 대해서 알아봤습니다. 이 방법이 옳다거나 절대적인 방법은 존재하지 않습니다. 그냥 이런식으로 해볼 수 있다는 것이지요. 이런 과정을 수 없이 반복하다보면 자연스럽게 데이터를 보는 힘이 강해질 겁니다. 다음 포스트에서는 데이터 전처리에 관해서 알아볼 예정입니다.
댓글남기기