
머신러닝 프로젝트 파이프라인(3)
이번 포스트에서는 저번 포스트에 이어 머신러닝 알고리즘을 위한 데이터 전처리 과정에 대해 설명하겠습니다.
Prepare the Data for Machine Learning Algorithms
전처리 방법도 마찬가지로 정해지거나 절대적인 방법이 따로 있는 것은 아닙니다. 개발하고자 하는 알고리즘에 맞게 혹은 데이터를 분석한 내용을 바탕으로 처리를 하시면 되는데, 일종의 커스터마이징이라고 생각하면 되겠습니다. 이번 포스트에서는 전처리에 필요한 라이브러리 같은 기본적인 내용을 알아가셨으면 좋겠습니다.
우선 처음 단계에서 supervised-learning 방식을 선택한다고 했으니, 데이터를 입력 값과 label 값으로 분리를 해줘야 합니다. housing dataset에서 median_house_value attribute 만 빼와서 label로 설정해줍니다.
housing = strat_train_set.drop("median_house_value", axis=1)
housing_labels = strat_train_set["median_house_value"].copy()
Data Cleaning
그 다음은 데이터에서 불필요한 요소를 제거 해야합니다. 대표적으로 null 값이 있겠죠. 이전 포스트에서 total_bedroom attribute에서 null 값이 존재하는 것을 확인했습니다. 이런 불필요한 요소를 다루는 것에는 크게 3가지 방법이 있습니다.
- null 값을 가지고 있는 데이터를 제거한다.
- 해당 attribute를 제거한다.
- null 값을 다른 값으로 대체한다.
housing.dropna(subset=["total_bedrooms"]) #1
housing.drop("total_bedrooms", axis=1) #2
median = housing["total_bedrooms"].median() #3
housing["total_bedrooms"].fillna(median, inplace=True)
각 방법에 관련된 코드입니다. 특히 3번째 방법은 중간 값을 대체하는 방식입니다. 이 방법을 활용할 때는 숫자 데이터에만 적용이 가능하고 카테고리 데이터에 대해서는 불가능합니다. 이 과정을 전체 attribute에 대해서 각각 적용하지 말고 Scikit-Learn에서 제공하는 SimpleImputer를 통해서 진행해보겠습니다. 우선 SimpulImputer 객체를 생성해주고 원래 데이터에서 카테고리 데이터를 뺴줍니다.
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="median")
housing_num = housing.drop("ocean_proximity", axis=1)
imputer.fit(housing_num)
그 다음 Imputer 객체를 fit()을 통해 데이터에 적용시킵니다. 아래 그림을 통해 잘 적용된 것을 확인할 수 있습니다.
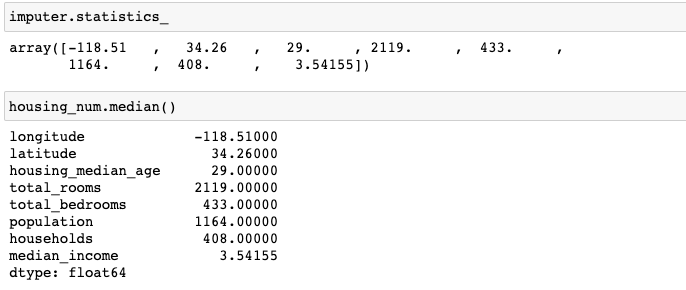
자, 그럼 적용된 Imputer를 가지고 아래 코드처럼 데이터를 변형시켜 보겠습니다.
X = imputer.transform(housing_num) #X:numpy.ndarray
housing_tr = pd.DataFrame(X, columns=housing_num.columns, index=housing_num.index)
아래 그림처럼 데이터가 잘 처리된 것을 확인할 수 있습니다.
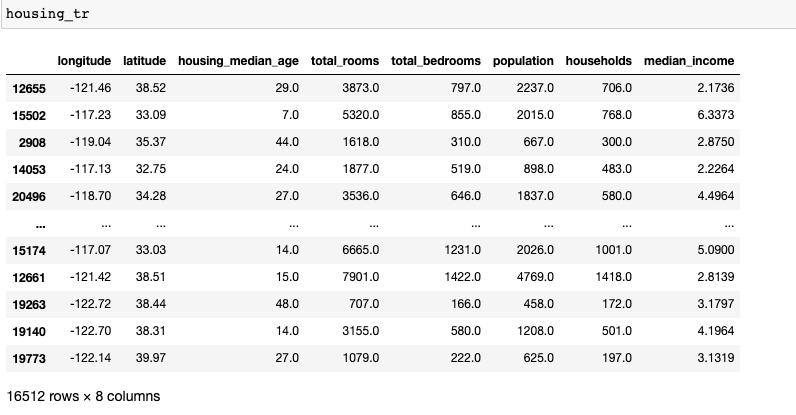
그리고 null이었던 데이터가 없는 것을 확인할 수 있습니다.
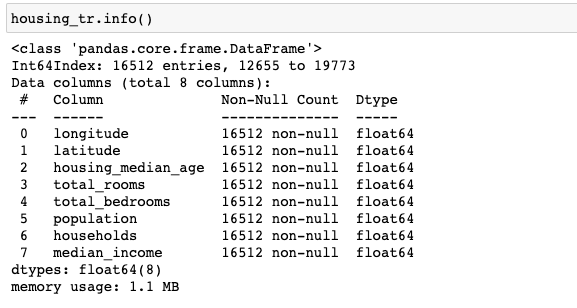
Handling Text and Categorical Attribute
지금까지, numeric 데이터에 대해서 null 값 또는 불필요한 값을 처리하는 방법에 대해서 알아봤습니다. 다음은 categorical 또는 text data에 대해서 살펴보도록 하죠.
housing 데이터에서 category 데이터인 ocean_proximity attribute를 통해 알아보겠습니다.
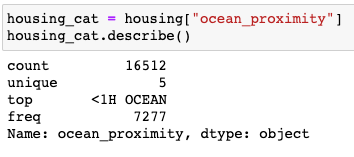
총 5개의 데이터 카테고리로 이루어져 있는 것을 확인할 수 있습니다. 텍스트로 이루어져 있기 때문에 컴퓨터가 받아들일 수 있도록 각각의 카테고리를 숫자로 표현해주어야 합니다. 예를 들어, 성별이라고 했을 때, ‘남’은 0으로 ‘여’는 1로 설정해줘야 합니다. 하나하나 바꿔주기 번거롭기 때문에 이를 위해서 Scikit-Learn에서 OrdinalEncoder를 활용해보겠습니다.
from sklearn.preprocessing import OrdinalEncoder
ordinal_encoder = OrdinalEncoder()
housing_cat_encoded = ordinal_encoder.fit_transform(housing_cat)
housing_cat_encoded[:10]
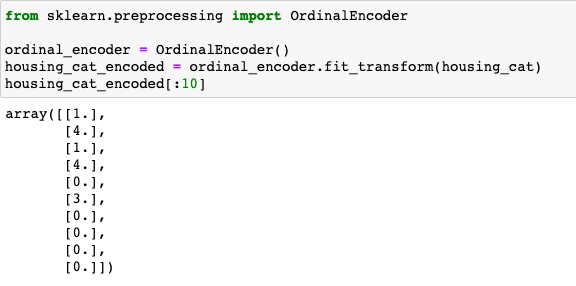
총 5개의 카테고리 별로 0에서 4까지 숫자로 인코딩이 되었습니다. 이렇게 특정 숫자로 인코딩할 수도 있지만 실제로는 벡터로 주로 표현을 합니다. 그 중에서 가장 기본적인 방법은 one-hot encoding 방식인데요. 말 그대로 하나의 원소만 1인 벡터를 의미합니다. 4로 인코딩된 카테고리는 one-hot vector로 표현하면 [0, 0, 0, 0, 1]이 됩니다.
from sklearn.preprocessing import OneHotEncoder
cat_encoder = OneHotEncoder()
housing_cat_1hot = cat_encoder.fit_transform(housing_cat)
housing_cat_1hot.toarray()
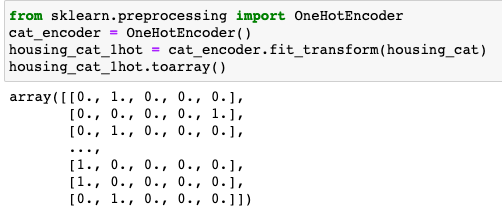
원 핫 인코딩은 기본적인 방법이지만 굉장히 sparse하다는 단점을 가지고 있습니다. 말 그대로 벡터의 크기에 비해서 가지고 있는 정보량이 매우 희소하다는 것이죠. 따라서 카테고리가 굉장히 많은 데이터에 대해서는 원 핫 인코딩을 활용한다면 벡터의 크기가 매우 커져 모델을 훈련시키는 데에 비효율적이 됩니다. 이를 해결하기 위해서 embedding이라는 개념이 존재하는데요. 간단하게 소개하자면 데이터 별로 표현하는 법을 학습하는 것을 의미합니다. 그러면 원 핫 인코딩보다 벡터의 크기는 작지만 효율적으로 데이터를 표현할 수 있겠죠. sparsity 문제를 해결할 수 있다는 것입니다. embedding에 대해서는 추후 자세하게 다룰 예정입니다.
Custom Transformers
전처리를 도와주는 여러 함수들을 합쳐서 본인 만의 transformer 전처리기를 만들 수도 있습니다.
from sklearn.base import BaseEstimator, TransformerMixmin
rooms_ix, bedrooms_ix, population_ix, households_ix = 3, 4, 5, 6
class CombinedAttributesAdder(BaseEstimator, TransformerMixmin):
def __init__(self, add_bedrooms_per_room = True):
self.add_bedrooms_per_room = add_bedrooms_per_room
def fit(self, X, y=None):
return self
def transform(self, X, y=None):
rooms_per_household = X[:, rooms_ix] / X[:, households_ix]
population_per_household = X[:, population_ix] / X[:, households_ix]
if self.add_bedrooms_per_room:
bedrooms_per_household = X[:, bedrooms_ix] / X[:, households_ix]
return np.c_[X, rooms_per_household, population_per_household, bedrooms_per_household]
else:
return np.c_[X, rooms_per_household, population_per_household]
앞서 진행했었던 기존 attribute들을 조합해서 새로운 attribute를 만들어내는 전처리기 transformer입니다.
Feature Scaling
데이터의 attribute 별로 scale이 다른 경우가 존재합니다. housing 데이터만 봐도 number of rooms의 범위는 6~39,320인데 반해 median incomes는 0~15인 것을 확인할 수 있습니다. 이처럼 데이터의 attribute 간의 scale이 크게 차이가 난다면 머신러닝 모델이 훈련하는 데에 방해요소가 될 수 있습니다. 이는 추후에 모델을 훈련시키는 방법인 경사하강법 Gradient Descent에서 더 자세히 다루고 지금은 파이프 라인에 대한 전반적인 설명이기 때문에 넘어가도록 하겠습니다.
Feature Scaling의 기본적인 방법에는 두 가지 방법이 있습니다: 1. normalization, 2. standardization.
Normalization
데이터를 0~1 사이의 값으로 스케일링하는 방법입니다. 구하는 식은 아래와 같습니다.
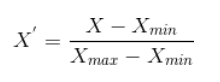
Standardization
데이터를 정규분포로 표현하는 방법입니다. 값의 범위는 따로 정해져있지 않고 평균 값을 뺀 다음 표준편차로 나눈 값을 의미합니다.
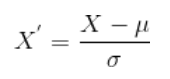
위 두가지 방법 모두 Scikit-Learn에서 라이브러리로 제공해주고 있습니다.
Transformation Pipelines
지금까지 전처리 과정을 하나하나 살펴봤는데요. 이것을 따로 진행을 한다면 번거롭겠죠. 그래서 한번에 원하는 전처리가 이루어지도록 전처리 파이프라인을 만드는 방법을 소개해드리겠습니다.
먼저, numeric attribute에 대해서 데이터에서 필요하지 않은 값을 median 값으로 대체한 후, 기존 attribute를 활용해서 새로운 attribute를 추가해주고 데이터를 정규분포화시키는 전처리기를 만들어보겠습니다.
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
num_pipeline = Pipeline([
('imputer', SimpleImputer(strategy="median")),
('attribs_adder', CombinedAttributesAdder()),
('std_scaler', StandardScaler()),
])
housing_num_tr = num_pipeline.fit_transform(housing_num)
그 다음은 categorical attribute를 원핫인코딩하는 전처리기를 추가해 전체적인 전처리기를 만들어보겠습니다.
from sklearn.compose import ColumnTransformer
num_attribs = list(housing_num)
cat_attribs = ["ocean_proximity"]
full_pipeline = ColumnTransformer([
("num", num_pipeline, num_attribs),
("cat", OneHotEncoder(), cat_attribs),
])
마지막으로 데이터를 최종 전처리기를 통해 전처리를 진행했을 때, 결과입니다. 잘 동작하는 것을 확인할 수 있지요.
지금까지, 데이터 전처리 과정에 대해서 알아봤습니다. 다음 포스트에서는 모델을 선택해서 훈련하고 실제로 결과를 뽑아보는 과정에 대해서 다루고 파이프라인에 대한 포스팅을s 마칠 예정입니다.
댓글남기기