
머신러닝 프로젝트 파이프라인(4)
이번 포스트에서는 저번 포스트에 이어 머신러닝 모델을 선택하고 훈련하는 과정에 대한 내용을 다룹니다.
Select and Train a Model
Training and Evaluation on the Training Set
사실 모델을 선택하는 데 있어서 절대적인 기준이나 방법은 존재하지 않습니다. 단지, 데이터를 분석하고 intuition을 얻으면서 그에 맞게 몇 가지 모델을 선택지에 놓고 실험을 진행한 다음 성능이 좋은 모델을 선택하게 되는 것이죠. 특정 모델이 어떤 특징을 가지고 있는지에 대해서는 추후에 모델들을 자세하게 다룰 때, 확인해보도록 하겠습니다. 딥러닝 모델을 설계하고 구축하는 것 이외에는 Scikit-Learn에서 대부분의 머신러닝 모델은 라이브러리로 제공해주고 있어서 모델을 구축하는 데에는 크게 어려움이 없습니다.
코드를 보겠습니다. 굉장히 간단합니다. 정말 Scikit-Learn에 감사할 따름이죠 ㅎㅎ
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(housing_preprocessed, housing_labels)
fit()을 통해 전처리된 housing 데이터로 LinearRegression 모델이 훈련이 됩니다. 이제 훈련용 데이터 중 일부 뽑아서 테스트를 해보겠습니다.
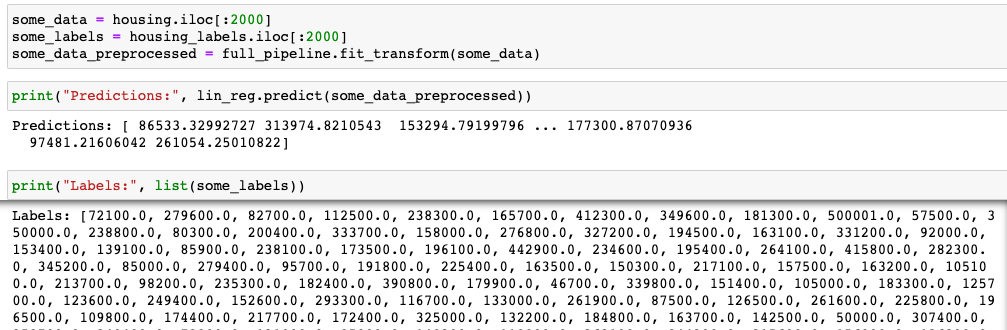
훈련했던 데이터로 결과를 확인해봤지만 차이가 많이 나는 것을 확인할 수 있습니다. 눈으로만 확인해보지 말고 loss를 계산해보겠습니다.
from sklearn.metrics import mean_squared_error
housing_predictions = lin_reg.predict(housing_preprocessed)
lin_mse = mean_squared_error(housing_labels, housing_predictions)
lin_rmse = np.sqrt(lin_mse)

Root Mean Squared Error를 통해서 loss를 구해봤는데, 눈으로 확인해본 것과 같이 차이가 많이 나네요…..
이는 모델이 이런 task와 데이터에 맞지 않는다는 것 또는 훈련을 잘못한 것을 의미합니다. 그런데 여기서는 갓Scikit-Learn 라이브러리를 활용했기 때문에 전자에 해당한다고 결론을 내릴 수 있겠죠. 그럼 모델을 달리해서 똑같이 돌려보겠습니다. 이번에는 결정트리 (DecisionTree) 모델로 돌려보겠습니다.
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(housing_preprocessed, housing_labels)

이전 모델과 달리 loss가 0이네요. 그런데 이것만 보고 훈련이 잘 되었다고 할 수 있을까요? 중요한 것은 지금 확인해본 것은 훈련용 데이터셋을 활용했다는 것입니다. 그렇죠. 이것이 바로 첫번째 포스트에서 확인했던 overfitting이라는 것입니다. 훈련용 데이터에 너무 과적합된 것이죠. 그럼 어떻게 해야할까요? 이 때 등장하는 것이 validation 단계입니다. 실제 테스트용 데이터셋으로 성능을 평가하기 전, validation 단계를 거치는 것입니다. 훈련용 데이터 셋의 일부를 validation 용 데이터 셋으로 분리해서 훈련이 잘 되었는지, 과적합은 안되었는지 확인하는 것입니다. 이제부터 Cross-Validation에 대해서 알아보겠습니다.
Cross-Validation
앞서 말한대로 기존의 훈련용 데이터셋을 다시 train/validation dataset으로 나눕니다. train dataset 안에서 훈련도 하고 중간점검도 한다는 것이죠. 그러면 validation dataset은 근본적으로는 훈련용 데이터 셋인데 훈련을 시키지 않으면 아깝겠죠? 그래서 등장한 방법이 K-fold Cross-Validation 입니다.
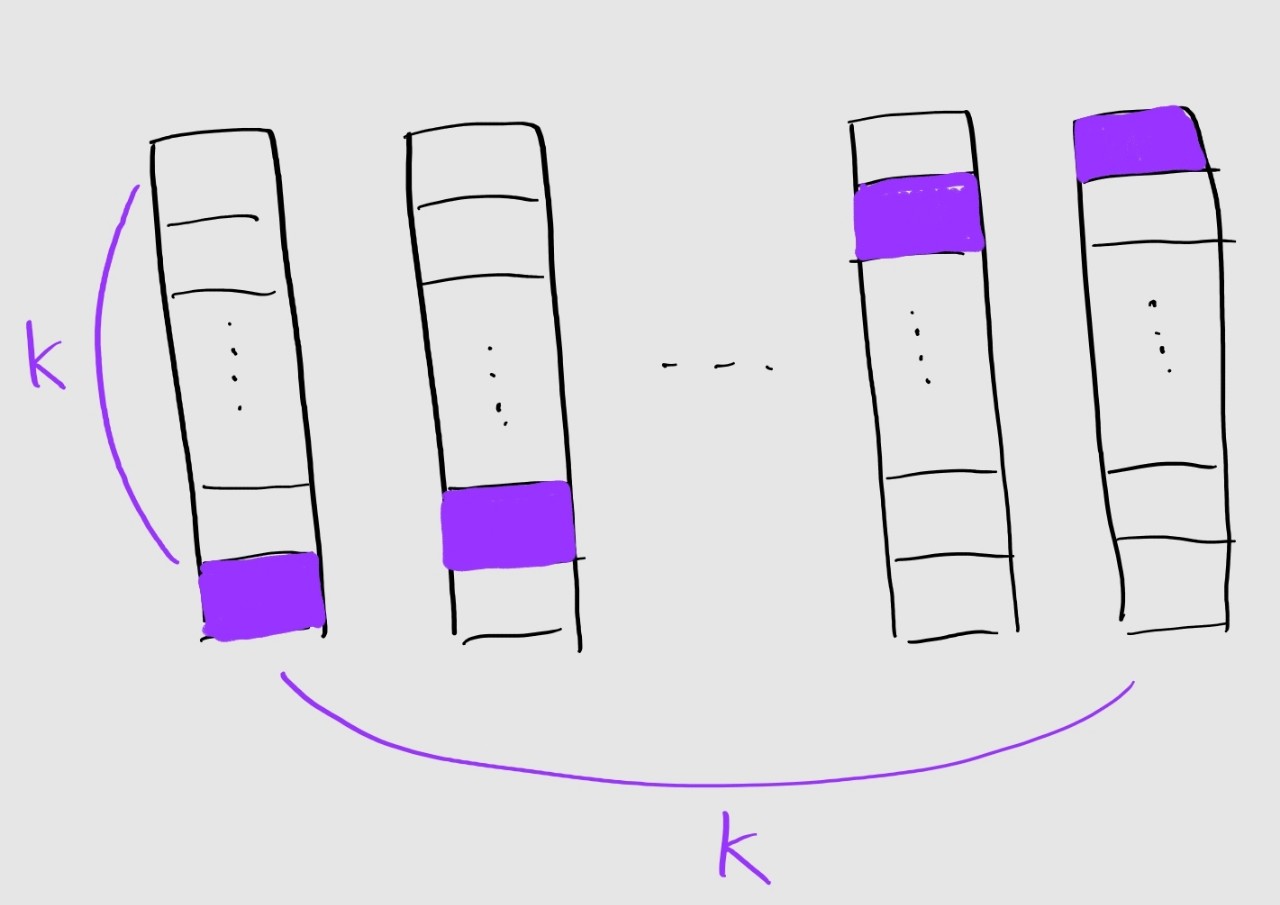
그림처럼 원래의 데이터 셋을 k개의 작은 조각으로 나눕니다. 이것을 fold라고 하는데요, 순서별로 각각 하나의 fold가 validation set이 되고 나머지 k-1개의 fold가 train set이 되서 훈련과 검증이 이루어집니다. 이 과정이 총 k번 이루어지겠죠. 그렇기 때문에 본래 한번의 훈련이 진행되었을 때와 달리 시간이 더 소모되기도 합니다. 하지만 훈련을 진행할 때 고정된 데이터 셋을 사용하는 것이 아니기 때문에 과적합이 일어날 가능성이 더 낮다는 장점을 가지고 있습니다. 이것도 갓 Scikit-Learn에서 라이브러리로 제공하고 있습니다. fold의 개수를 10으로 설정한 K-fold Cross-Validation을 코드로 확인해보시죠.
from sklearn.model_selection import cross_val_score
scores = cross_val_score(tree_reg, housing_preprocessed, housing_labels, scoring="neg_mean_squared_error", cv=10)
tree_rmse_scores = np.sqrt(-scores)
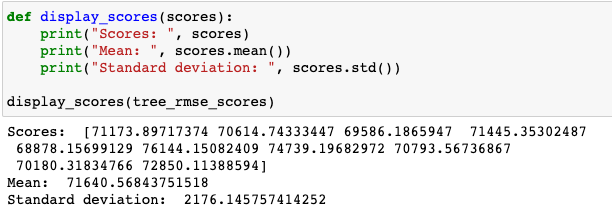
이전 loss가 0이었던 것과는 전혀 다른 결과가 나왔습니다. 그럼 liner regression에 cross validation을 적용해보겠습니다. 오히려 Decision Tree 보다 더 좋은 결과를 보여주는 것을 확인할 수 있습니다.

이처럼, 모델을 훈련하는 방법에 따라서 모델의 성능이 차이가 나기도 합니다. 지금까지 두 개의 모델; linear regression, decision tree를 통해서 모델 훈련과정에 대해서 설명드렸습니다.
Fine-Tune Model
지금까지 모델을 훈련하는 방법에 대해서 알아봤습니다. 하지만 한번으로 최고의 모델을 찾는 것은 불가능에 가깝죠. 그래서 다양한 시나리오를 바탕으로 여러 실험을 반복해야합니다. 모델 이외에도 시나리오를 구성하는 것 중 하나는 바로 Hyperparameter입니다. 새롭게 RandomForest 모델을 통해서 hyperparameter를 조정하는 방법에 대해서 알아보겠습니다.

RandomForestRegressor에는 세 가지 hyperparameter; bootstrap, n_estimators, max_features가 존재합니다. 이는 추후에 자세히 다룰 예정이니 지금은 hyperparameter를 조정하는 방법에 대해서 집중하겠습니다.
먼저, Grid Search입니다. 말 그대로 모든 조합으로 실험을 진행하는 것이죠.
from sklearn.model_selection import GridSearchCV
param_grid = [
{'n_estimators': [3, 10, 30], 'max_features': [2, 4, 6, 8]},
{'bootstrap': [False], 'n_estimators': [3, 10], 'max_features': [2, 3, 4]},
]
forest_reg = RandomForestRegressor()
grid_search = GridSearchCV(forest_reg, param_grid, cv=5,
scoring='neg_mean_squared_error', return_train_score=True)
grid_search.fit(housing_preprocessed, housing_labels)
위의 코드를 보면 총 2가지 조합세트가 있습니다. 각 세트 별로, 첫번째는 12가지, 두번째는 6가지 총 18가지의 조합이 나올 수 있겠죠.
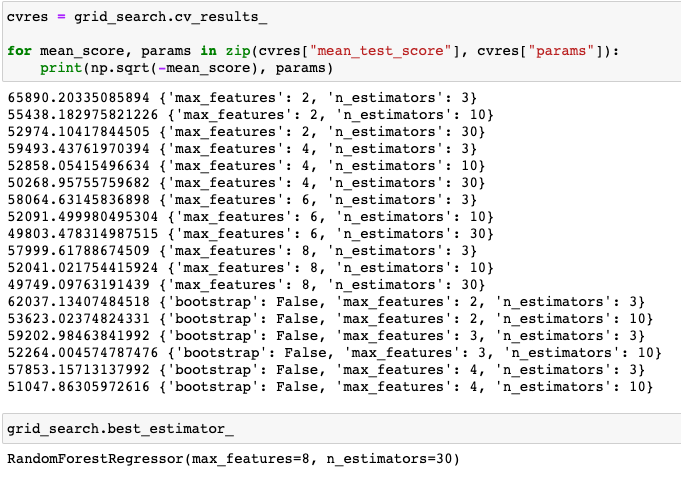
GridSearchCV에 모델과 파라미터 정보를 넣어주면 알아서 모든 시나리오대로 실험을 진행해줍니다. 그림처럼 결과도 확인할 수 있고 가장 좋은 조합에 대해서도 확인할 수 있습니다. 매우 편리하고 유용하네요. GridSearch 이외에도 Random Search와 Ensemble 방법이 있는데, Random Search는 말 그대로 모든 조합이 아닌 랜덤하게 조합을 이뤄서 일부만 실험을 한다는 것이죠. 조합의 수가 많을 때, 활용할 수 있는 방법 중 하나입니다. 그리고 Ensemble은 하나의 시나리오를 채택하기 보다는 모든 시나리오의 결과를 취합해서 최종 모델을 산출하는 개념인데요, 나중에 자세히 다룰 예정입니다.
Evaluate on the Test Set
이제 훈련을 마쳤고 훈련이 잘된 모델을 만들었으니 Test dataset에 대해서 평가를 해야겠지요. 그리 어렵지 않습니다. 훈련과 마찬가지로 데이터를 전처리 해주고 모델에 넣어서 성능만 뽑아내면 되니까요.
final_model = grid_search.best_estimator_
X_test = strat_test_set.drop("median_house_value", axis=1)
y_test = strat_test_set['median_house_value'].copy()
X_test_preprocessed = full_pipeline.transform(X_test)
final_predictions = final_model.predict(X_test_preprocessed)
final_mse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_mse)
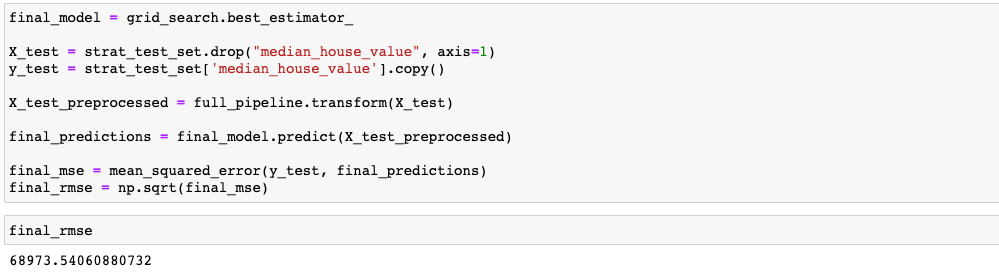
훈련대신 predict()를 통해서 테스트 데이터셋에 대해서 결과를 뽑아봤습니다.
이로써, 머신러닝 프로젝트의 전반적인 파이프라인에 대해서 알아봤습니다. 굉장히 간략하게 소개를 했는데 실제로 각 단계별로 많은 노력과 시간을 투자해야 좋은 프로젝트가 완성이 되겠죠. 다음 포스팅부터는 머신러닝의 좀 더 세부적인 내용을 깊게 알아보도록 하겠습니다.
댓글남기기