
1.Neural Machine Translation by Jointly Learning to Align and Translate (Paper Review)
이번 포스트에서 다룰 논문은 ICLR 2015에 개제된 Dzmitry Bahdanau, KyungHyun Cho, Yoshua Bengio 저자의 Neural Machine Translation by Jointly Learning to Align and Translate 입니다. 지금은 흔하게 사용되고 있는 어텐션 (attention)이란 개념을 최초로 제안한 논문입니다. 제목만 보고 Transformer 모델을 제안한 ‘Attention is all you need’에서 attention을 제안했다고 오해하기 쉬우니 주의 바랍니다. ‘Transformer 시대’ 라는 말이 나올 정도로 거의 모든 분야에서 Transformer 모델이 활용되고 있고 좋은 성능을 보이고 있는데요. Transformer 모델의 근간이 되는 attention 개념을 제안한 논문이기 때문에 ‘Attention is all you need’ 논문을 읽기 전에 꼭 읽어보시는 것을 추천드립니다.
Introduction & Background
우리가 자주 사용하고 있는 구글 번역기 혹은 파파고는 모두 Neural Network로 구현되었습니다. 일명 NMT(Neural Machine Translation) 이라고 하는데요. NMT가 도입되기 전에는 대부분 통계 모델 기반인 SMT(Statical Machine Translation) 오랜 기간동안 주를 이뤘습니다.
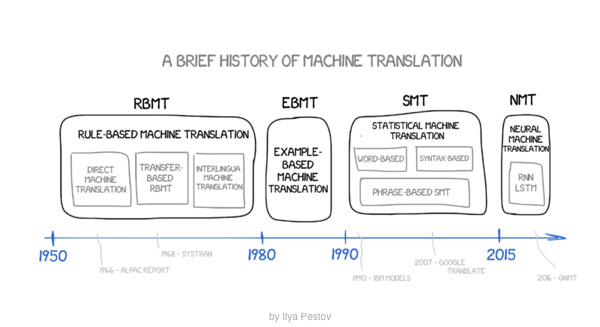
SMT는 하지만, 큰 단점을 가지고 있었습니다. 하나의 모델이긴 하지만 3 개의 세부 모델 (translation model, language model, alignment model)로 구성되기 때문에 어느 한 모델에서 수정이 생겨도 모든 모델에 영향을 주기 때문에 유지보수가 힘들고 비용이 많이 듭니다.
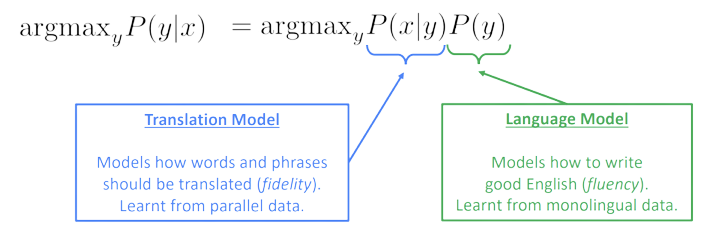 출처: "https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/slides/cs224n-2019-lecture08-nmt.pdf"
출처: "https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/slides/cs224n-2019-lecture08-nmt.pdf"
위 그림에서, 왼쪽이 확률 기반의 모델을 의미하는 데 이는 베이즈 룰에 의해서 오른쪽과 같이 표현이 가능합니다. 오른쪽 P(x|y)는 translation model을 의미하고 P(y)는 language model을 의미합니다. 따라서, 확률 기반 모델은 translation model, language model로 세분화 될 수 있습니다. 또한, 번역하고자 하는 source text의 어느 단어 혹은 phrase가 Target text의 어는 component와 매칭 (align)이 되는지도 모든 경우의 수를 따져봐야합니다. 이를 담당하는 것이 alignment model입니다. 그래서 총 3 개의 세부 모델 (translation model, language model, alignment model)이 필요한 것이죠.

출처: "https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/slides/cs224n-2019-lecture08-nmt.pdf"
하지만 위의 사진처럼 모든 alignment의 경우의 수는 굉장히 많죠. 하지만 번역 모델의 이렇다할 경쟁상대가 없었기 때문에 오랜 기간동안 SMT가 주로 활용된 것입니다. 그러던 중에, Seq2Seq 모델이 등장하면서 주류는 SMT에서 NMT로 넘어가게 되었습니다.
SMT와 다르게 NMT는 유지보수가 굉장히 용이하죠. 데이터만 있으면 모델이 알아서 훈련을 하기 때문에 세 가지 세부 모델로 구성된 SMT에 비해 사람이 손수 관리해야하는 부분은 많지 않은 것입니다. 게다가 Seq2Seq 모델의 등장으로 더 높은 성능까지 보여주게 되었죠. 하지만 Seq2Seq 모델에도 한계점이 존재했는데요. 그것은 바로 아래 사진처럼 Bottleneck 문제가 발생한다는 것입니다. Seq2Seq 모델의 Encoder는 Source text의 정보를 압축해서 하나의 context vector로 표현을 하는데요, text의 길이가 길어지면서 한정된 크기의 vector로 모든 정보를 담아내기 힘들다는 것이죠.
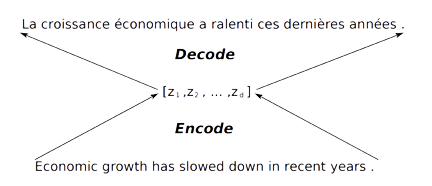
출처: "https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/slides/cs224n-2019-lecture08-nmt.pdf"
이러한 문제를 해결하고자 attention이 고안되었고 이 논문을 통해 제안되었습니다. 자, 이제 함꼐 살펴보시져.
Learning To Align and Translate
이 논문은 Alignment 개념을 도입했는데 이는 추후에 우리가 잘 알고 있는 Attention이라고 부르게 됩니다. 목표는 명확합니다. Seq2Seq 모델의 Bottleneck 문제를 해결하는 것이죠. 사람에 비유해서 표현을 하자면, Seq2Seq 모델은 Source text 한 번 읽은 다음 기억에 의존해서 번역을 진행하는 것이라면 Attention은 번역을 진행하는 동안에도 계속 Source text를 보고 참고해서 번역을 진행하는 것이라고 보면 됩니다.

출처: "https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/slides/cs224n-2019-lecture08-nmt.pdf"
위의 그림을 보면, 좌측 Seq2Seq 모델에서 Context vector c는 상수 인데 반해 우측 attention을 적용한 Seq2Seq 모델에서 Context vector는 ci로 변수인 것을 확인할 있습니다.
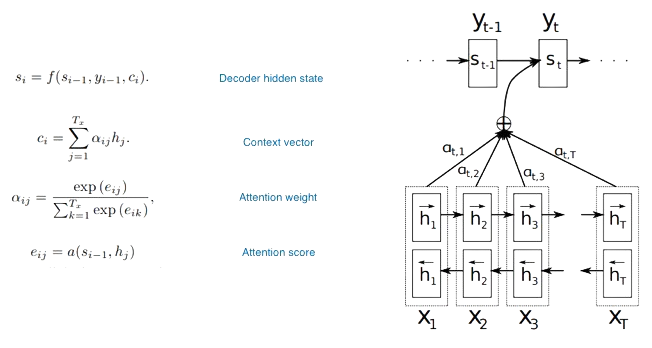
출처: "https://arxiv.org/pdf/1409.0473.pdf"
Attention은 쉽게 말해서 원하는 결과와 가장 연관이 높은 요소를 찾는 과정이라고 보시면 됩니다. Query, Key, Value들의 연산으로 이루어져 있는데요. 여기서 Query는 연관성을 구하는 데 어떠한 기준이고, Key와 Value는 그 기준에 맞춰 연관성을 구해야하는 요소들이라고 보시면 됩니다. 위의 그림 우른쪽 사진을 예로 들었을 때, Qeury는 디코딩 시 이전 hidden state 값이고, Key와 Value는 Encoder의 hidden state 값들이라고 할 수 있습니다. 각각의 tiemstep별 디코딩을 진행할 떄, 이전 hidden state 값들과 Encoder의 hidden state 값들과의 연과성을 구해 이번 timestep의 결과가 source sentence의 어떤 단어와 연관이 가장 높은지 계산하는 것으로 이해하시면 되겠습니다.
Attention은 세 가지 과정을 통해서 구해지게 된다. 첫 번째는 Attention score를 구하는 과정, 두 번째는 Attention weight을 구하는 과정이고 마지막으로 최종 Context vector를 구하는 과정이다.
- Attention score
Attention score는 말 그대로, Query와 Key 간의 연관성을 의미한다. 연관성을 구하는 방법은 따로 정해지진 않고 내적, 더하기 혹은 따로 neural network로 구성하는 등 다양하게 존재한다. 이 논문에서는 Query와 Key간의 가중치 합으로 Attention score를 구하는 데 학습을 통해 가중치들을 업데이트하는 neural network 방법을 활용한다.
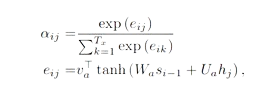
출처: "https://arxiv.org/pdf/1409.0473.pdf"
-
Attention weight
Attention weight은 Softmax 함수를 활용해서 Attention score들의 합이 1이 되게 끔, 비율적인 측면으로 변형 시켜줍니다. -
Context vector
이전 단계에서 구한 Attention weight을 Value인 Encoder의 Hidden state 값들과 가중치 합을 해 구해지게 됩니다. timestep 별로 가장 관련이 높은 Encoder의 Hidden state 값이 반연된 Context vector가 생성되게 됩니다.
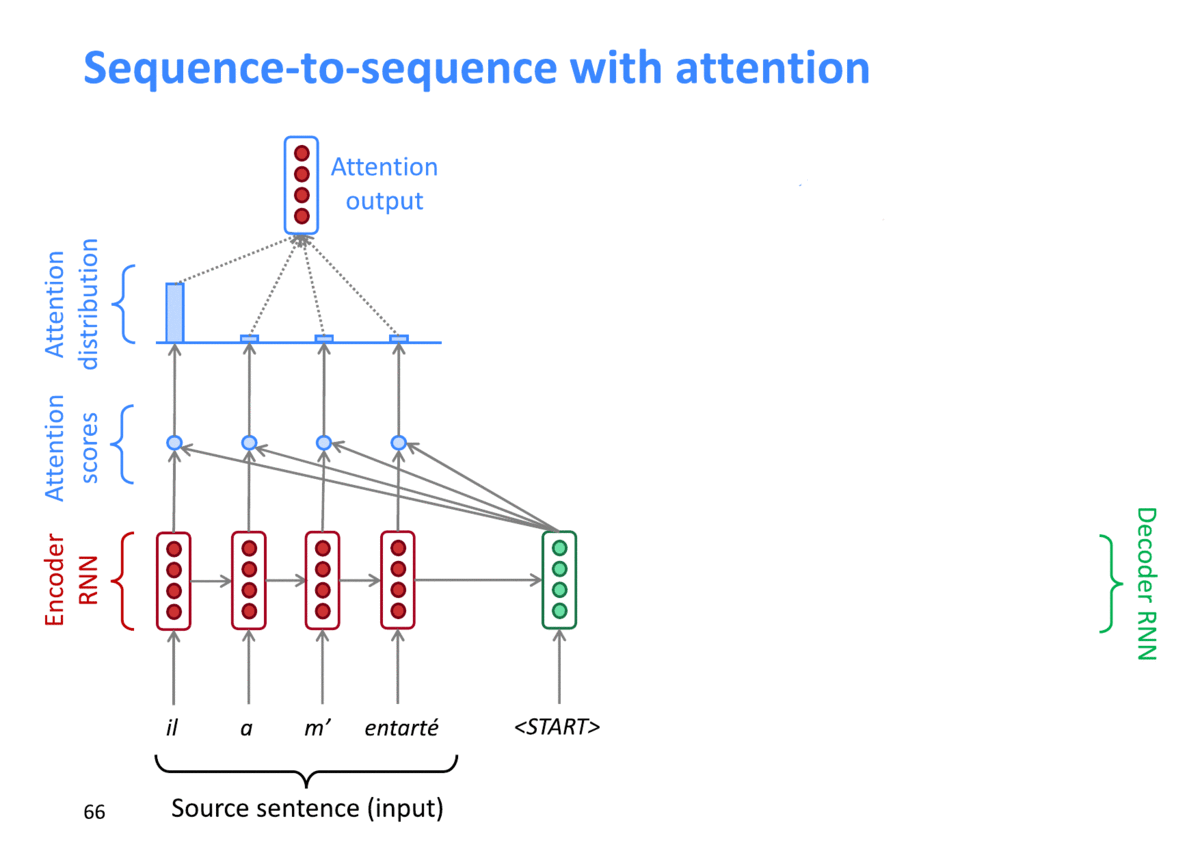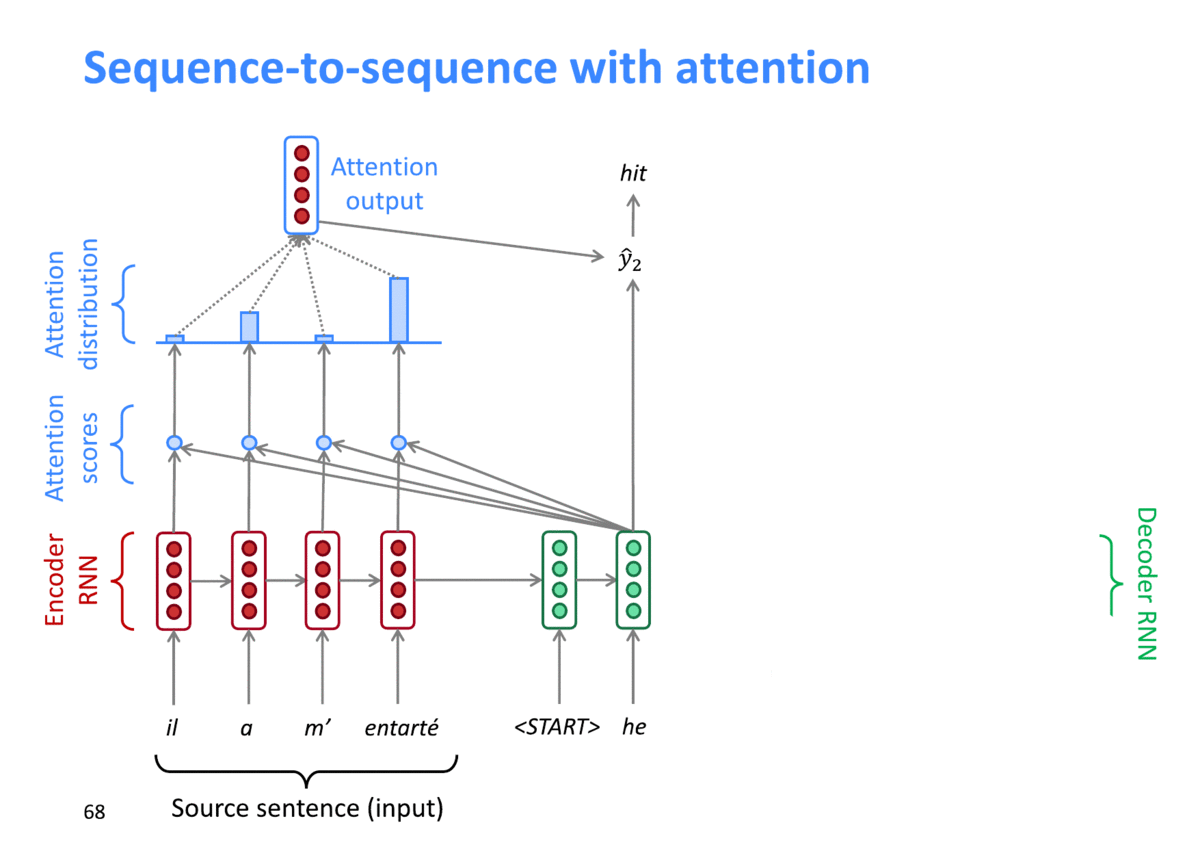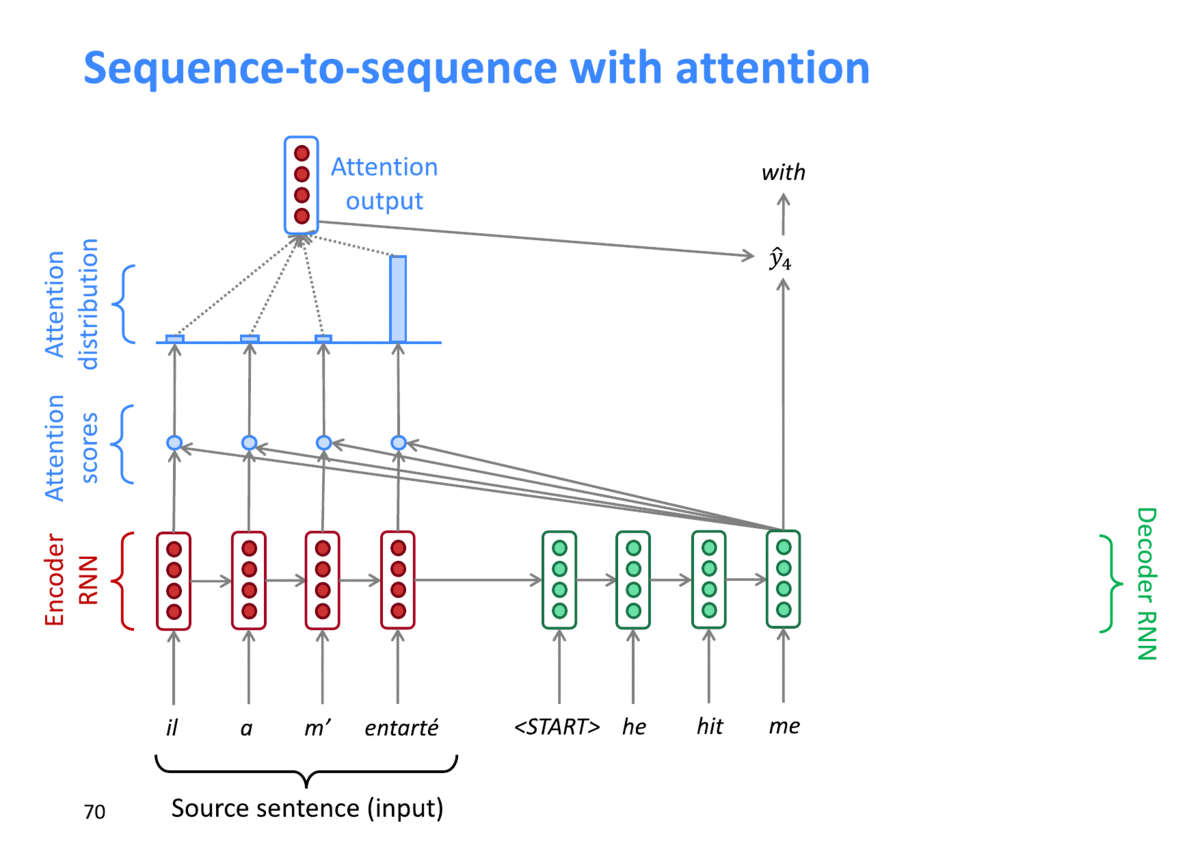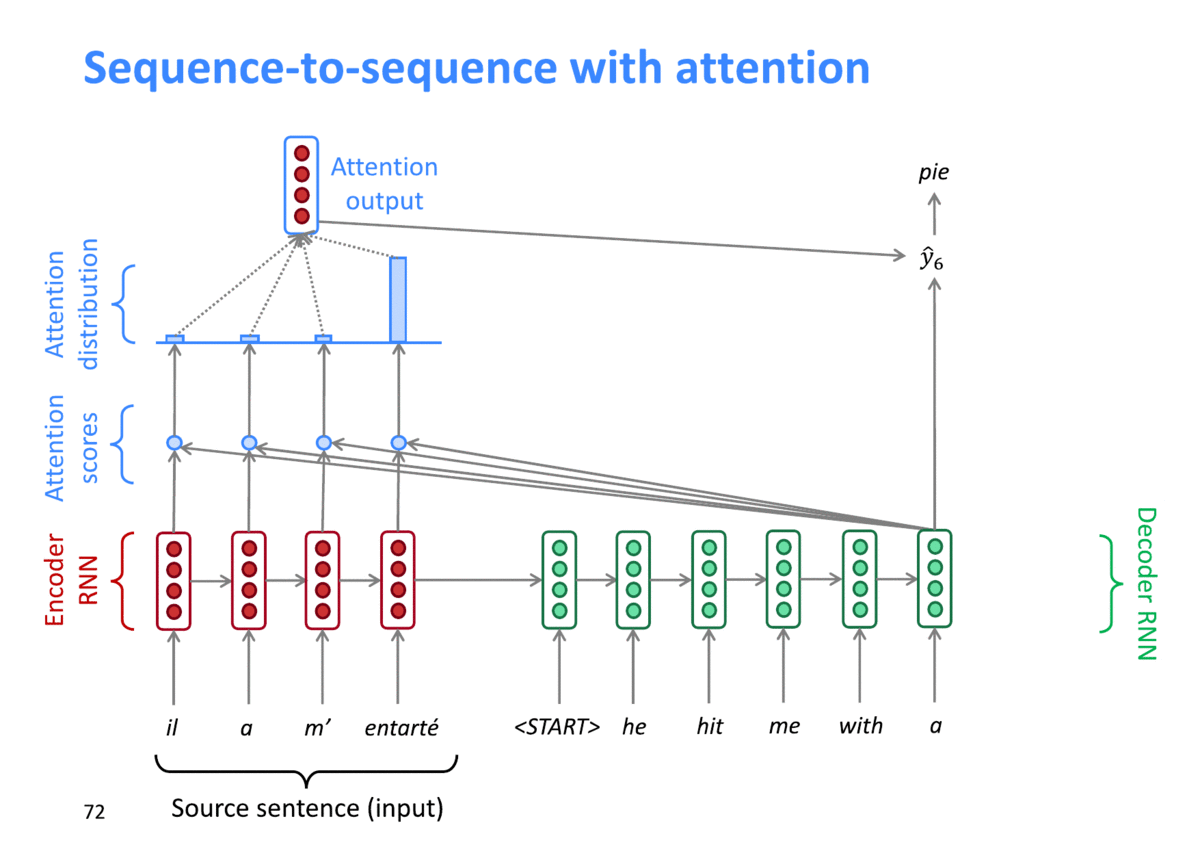
출처: "https://arxiv.org/pdf/1409.0473.pdf"
위 그림처럼, 디코딩시 각 timestep별로 서로 다른 attention weight (attention distribution)이 구해지는 것을 확인할 수 있고 이를 통해 서로 다른 Context vector가 디코딩 결과에 영향을 주게 됩니다.
Experiments & Result
-
Dataset
WMT`14는 348M 개의 단어로 구성된 corpus 데이터 셋입니다. Europarl, news commentary, UN 데이터 셋과 두 개의 크롤링된 corpora로 구성되어 있습니다. - Experiment
- Seq2Seq model vs Seq2Seq with attn model
- 1000 hidden units
- Bi-directional
- 30 words and 50 words training
- BLEU score를 활용해 성능 평가
- Result

출처: "https://arxiv.org/pdf/1409.0473.pdf"
RNNencdec는 기존 Seq2Seq 모델, RNNsearch는 Seq2Seq with attn 모델, Moses는 SMT 모델을 나타냅니다. 위 표의 결과를 봤을 때, 우선 30 words와 50 words로 훈련한 모델에서 Attention 모델이 Seq2Seq모델에 비해 높은 성능을 보였습니다. 이는 Attention의 효과를 입증하는 것이라고 볼 수 있습니다. 또한 Moses SMT와 비교했을 때, (RNNsearch-50 보다 더 많이 훈련된) RNNsearch-50*이 높은 성능을 보이는 것을 확인할 수 있습니다.
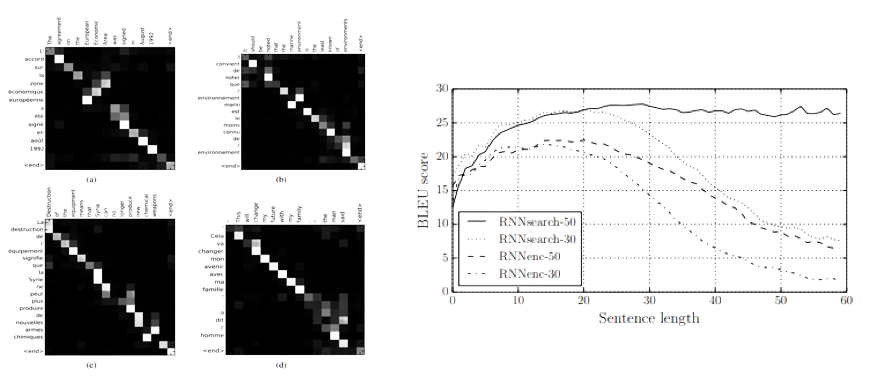
출처: "https://arxiv.org/pdf/1409.0473.pdf"
위 왼쪽 그림은 Attention weight을 heatmap으로 표현한 것인데요. 하얀색일 수록 높은 연관이 있음을 나타냅니다. 대각선 이외에도 하얀 부분이 나타나있는 것을 확인할 수 있습니다. 이는 position에 dependent한 것이 아니라 실제로 모델이 연관된 단어들을 찾아내도록 훈련이 진행되는 것을 알 수 있습니다. 오른쪽 그림은 문장이 길어질 수록 Seq2Seq 모델의 성능이 떨어지지만 Attention을 적용한 모델은 성능을 유지하는 것을 나타냅니다. 이를 통해 기존의 긴 문장에서 나타나는 Bottlenect 문제가 해결이 된다는 것을 확인할 수 있죠.
지금까지 Attention mechanism을 도입한 Neural Machine Translation by Jointly Learning to Align and Translate 논문에 대해서 살펴보았습니다. 이후에는 Transformer를 시작으로 BERT 등의 다양한 Large scale의 Pre-trained 모델에 대한 논문을 살펴볼 예정입니다. NLP 위주로 논문을 리뷰할 예정이지만 공부를 하다가 흥미로운 논문이나 중요한 논문이 있으면 리뷰하도록 하겠습니다.
댓글남기기